【統計検定準一級】統計学実践ワークブックの問題をゆるゆると解く#21
【概要】
【目次】
はじめに
本シリーズでは、いろいろあってリハビリも兼ねて統計学実践ワークブックの問題を解いていきます。 統計検定を受けるかどうかは置いておいて。
今回は9章「区間推定」から1問。
なお、問題の全文などは著作権の問題があるかと思って掲載してないです。わかりにくくてすまんですが、自分用なので。
心優しい方、間違いに気付いたら優しく教えてください。
問9.1
問題
内閣支持率の世論調査を実施し、1,240人から回答があった。この回答を集計すると支持率は43%であった。(本当の調査かは知らないです)

(1) 回答者が母集団からの無作為抽出であると仮定したとき、95%信頼区間を求めよ
確率pで支持、(1-p)で不支持とすると、43%という集計結果は二項分布に従うことになります。
二項分布はベルヌーイ分布に従う確率変数の和となるので、中心極限定理からこれは正規分布で近似できることがわかります。
すると、二項分布の期待値と分散から、標準正規分布に従うz-scoreを導出できます。

このz-scoreが95%信頼区間の標準正規分布での下限と上限にかかる値を求めることで、信頼区間がもとまります。

この辺りの証明は、参考文献2を参考にしました。
(2) 支持率が40%前後と仮定したとき、95%信頼区間が2%となるために必要なサンプルサイズを求めよ
信頼区間の範囲から、幅は以下の式の通りとなります。
ここで、1.96は95%信頼区間なので1.96です。標準正規分布での2.5%, 97.5%の位置ですね。

参考資料
[1] 日本統計学会, 統計学実践ワークブック, 2020, 学術図書出版社

日本統計学会公式認定 統計検定準1級対応 統計学実践ワークブック
- 発売日: 2020/05/29
- メディア: 単行本
")
- 発売日: 1991/07/09
- メディア: 単行本
【統計検定準一級】統計学実践ワークブックの問題をゆるゆると解く#20
【概要】
- 統計検定準一級対応 統計学実践ワークブックの問題を解いていくシリーズ
- 第19回は8章「統計的推定の基礎」から1問(の半分)
- 8章も厳しかった
【目次】
はじめに
本シリーズでは、いろいろあってリハビリも兼ねて統計学実践ワークブックの問題を解いていきます。 統計検定を受けるかどうかは置いておいて。
今回は8章「統計的推定の基礎」から1問。
なお、問題の全文などは著作権の問題があるかと思って掲載してないです。わかりにくくてすまんですが、自分用なので。
心優しい方、間違いに気付いたら優しく教えてください。
問8.3
今回は、前回の続きです。問8.3長い。
問題
コイン工場で作られた5枚のコインについて。半径は以下の通り。
(4) ジャックナイフ推定量を用いてコインの面積のバイアス補正推定値を求めよ
(3)と同様に、についてバイアスを補正した推定量を求めます。
バイアスの補正には「ジャックナイフ法」という手法を用いますが、この手法の証明等については追っておらず、テキストに記載の通りに実行しました。

このような標本を分割してバイアスを補正するなど推定値の精度を向上させる手法を「リサンプリング法」と呼ぶらしいです。手法としては手軽なので、何かで実用してみたいですね。
(5) デルタ法を用いてT1の漸近正規性を示せ
デルタ法というのは、7章で出てきたもので、の分布収束先を求める方法ということです(これも証明は追えていないです)。
ここでは、なので、以下のメモの通りに漸近分散を求めることができます。

参考資料
【統計検定準一級】統計学実践ワークブックの問題をゆるゆると解く#19
【概要】
- 統計検定準一級対応 統計学実践ワークブックの問題を解いていくシリーズ
- 第19回は8章「統計的推定の基礎」から1問(の半分)
【目次】
はじめに
本シリーズでは、いろいろあってリハビリも兼ねて統計学実践ワークブックの問題を解いていきます。 統計検定を受けるかどうかは置いておいて。
今回は8章「統計的推定の基礎」から1問。
なお、問題の全文などは著作権の問題があるかと思って掲載してないです。わかりにくくてすまんですが、自分用なので。
心優しい方、間違いに気付いたら優しく教えてください。
問8.3
問題
コイン工場で作られた5枚のコインについて。半径は以下の通り。
(1)  の二つの推定量についてバイアスを求めよ
の二つの推定量についてバイアスを求めよ
二つの推定量については以下のメモを参照してください(見難くてすまんです。テキストを入手してください)。
バイアスは推定量の期待値から真値を引いたものなので、まずは推定量の期待値を求めます。今回の二つの推定量は、分散の式を利用して以下のメモのように導出できます。
推定量の期待値が導出できれば、あとは真値を引くだけ。

(2) コインの面積 の推定値を各コインの面積の平均とすることの問題点
の推定値を各コインの面積の平均とすることの問題点
各コインの面積の平均は(1)のT2の推定量のπ倍の値になります。
そのため、(1)で求めたバイアスから、この推定値にはデータ数によらないバイアスが入ってしまいます。(つまり、不偏性がない)

(3) バイアスを補正した推定量を用いて、コインの面積のバイアス補正推定値を求めよ
(1)のT1のを以下のように補正するとのことです。
ここで、Uは不偏分散です。
なので面積の推定値は
となります。これを愚直に計算すると以下のメモのようになります。

参考資料
【統計検定準一級】統計学実践ワークブックの問題をゆるゆると解く#18
【概要】
- 統計検定準一級対応 統計学実践ワークブックの問題を解いていくシリーズ
- 第18回は8章「統計的推定の基礎」から1問
【目次】
はじめに
本シリーズでは、いろいろあってリハビリも兼ねて統計学実践ワークブックの問題を解いていきます。 統計検定を受けるかどうかは置いておいて。
今回は8章「統計的推定の基礎」から1問。
なお、問題の全文などは著作権の問題があるかと思って掲載してないです。わかりにくくてすまんですが、自分用なので。
心優しい方、間違いに気付いたら優しく教えてください。
問8.2
問題
ポアソン分布に従って独立同一で取得されたn個の標本について。
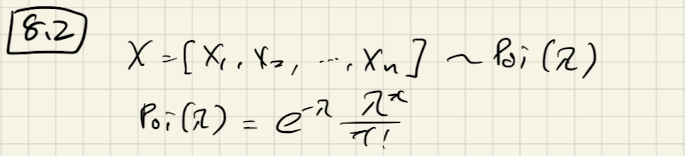
(1) パラメータ の最尤推定量を求めよ
の最尤推定量を求めよ
最尤推定量ということで、対数尤度関数の微分を求めれば良いです。

(2) に関するフィッシャー情報量を求めよ
フィッシャー情報量はn個のデータについて以下の式で定義されています。(こちらの記事、参考文献3を参照)
対数尤度の微分の2乗の期待値です。
フィッシャー情報量の性質として、
は標本一つの情報量のn倍という性質があります(以下のメモ)。また二乗の期待値の形を二階微分を使って表現することができます(以下のメモ)。これらの詳細は参考文献3などに詳しく書かれています。
これらを利用して、フィッシャー情報量は以下のメモの様に導出できます。

(3) の最尤推定量が有効推定量であることを示せ
有効推定量とは、推定量の分散がフィッシャー情報量の逆数に等しくなることです(クラーメル・ラオの不等式の下限、こちらの記事、参考文献3)。ということで、最尤推定量の分散を求めます。

ということで、有効推定量であることがわかりました。
(4) の最尤推定量の漸近正規性、漸近有効性を示せ
最尤推定量は標本平均です。標本平均は中心極限定理から漸近的に正規分布
に収束します(参考文献2,
参考文献3)。なので、漸近正規性が言えます。
漸近分散がフィッシャー情報量の逆数になることもそのまま出てきていますので、漸近有効であることもわかりました。

参考資料
【統計検定準一級】統計学実践ワークブックの問題をゆるゆると解く#17
【概要】
- 統計検定準一級対応 統計学実践ワークブックの問題を解いていくシリーズ
- 第17回は8章「統計的推定の基礎」から1問(#16の続き)
【目次】
はじめに
本シリーズでは、いろいろあってリハビリも兼ねて統計学実践ワークブックの問題を解いていきます。 統計検定を受けるかどうかは置いておいて。
今回は8章「統計的推定の基礎」から1問。8章はいきなり厳しくて、参考書を2冊追加してます(会社の経費で買った)。
なお、問題の全文などは著作権の問題があるかと思って掲載してないです。わかりにくくてすまんですが、自分用なので。
心優しい方、間違いに気付いたら優しく教えてください。
問8.1
今回は、前回この問題については挑戦したのですが、(5)がよくわからなかったので再度やり直しています。
問題
正規分布からi.i.dで得た標本
について
(5) 標本分散は分散 の一致推定量であるが、漸近有効推定量ではないか?
の一致推定量であるが、漸近有効推定量ではないか?
まず、一致推定量であるかを確認します。一致推定量の定義から、推定量の分散とバイアスがの極限で共に0になることが条件となります。これらを確認して一致性を持つと言うことが確認できました。なお、標本分散の分散とバイアスはこちらも合わせて参照ください。
「漸近有効性」については、調べたのですがまだよくわかっていません。正規分布の最尤推定量は漸近有効という記載はいくつかの書籍で確認したのですが、証明を追えていません。。。

参考資料
[1] 日本統計学会, 統計学実践ワークブック, 2020, 学術図書出版社
日本統計学会公式認定 統計検定準1級対応 統計学実践ワークブック
- 発売日: 2020/05/29
- メディア: 単行本
- 発売日: 1991/07/09
- メディア: 単行本
[3] 矢島ら, 自然科学の統計学, 1992, 東京大学出版会
")
- 発売日: 1992/08/01
- メディア: 単行本
[4] 久保川, 現代数理統計学の基礎, 2017, 共立出版
")
- 作者:達也, 久保川
- 発売日: 2017/04/07
- メディア: 単行本
[5] 竹村, 現代数理統計学, 2021, 学術図書出版社

- 作者:彰通, 竹村
- 発売日: 2020/11/10
- メディア: 単行本
【統計検定準一級】第8章 統計的推定の基礎 #4【番外編】
【概要】
- 統計検定準一級対応 統計学実践ワークブックの問題を解いていくシリーズの番外編
- 8章「統計的推定の基礎」の内容をまとめます
- 今回は推定量を評価する基準として、サンプルサイズが大きいときの漸近的な性質を議論します
- 正直理解できてないです。折を見て再度挑戦しよう
- おまけとして、不偏分散の導出も載せています
【目次】
はじめに
「統計学実践ワークブック(参考資料1)」の問題を解いていくシリーズをやっていく中で、8章「統計的推定の基礎」の内容をさっぱり理解していないことがわかったので、改めて整理しています。
参考にした資料は参考文献に列挙しています。中でも主に文献4を参考にしています。
心優しい方、間違いに気付いたら優しく教えてください。
8章の流れ
統計の目的の一つとして、「未知パラメータの推定」という問題があり、この章ではその中でも「点推定」について扱っています*1。「区間推定」については9章で扱われています。
- 情報の集約
- 推論を行うにあたって、生データを全て保存するのではなく、情報を集約できればうれしい(メモリ的に)
- → 「十分統計量」
- 推定法
- パラメータの点推定を行うためにはいくつか方法がある
- → モーメント法
- → 最尤推定
- 推定量の評価、推定量の性質
この流れに沿って、確認内容をまとめていこうと思います。
今回は推定量を評価する基準として、サンプルサイズが大きいときの漸近的な性質を議論します。
推定量の性質
前々回は、パラメトリックなモデルにおけるパラメータの推論方法として、「モーメント法」と「最尤法」を扱いました。
パラメータの推論方法は他にも事後確率最大化法(MAP推定)などの方法がありますが、それらの推定量の性質を評価して、どのような推定量が好ましいのかを議論していきます。
漸近的性質
標本サイズnが大きい時の推定量の性質がわかれば、推定量が良いものか判断できます。
一致性(consistency)
推定量が一致性を持つとは、以下のようにnを大きくしていくと
が真のパラメータ
に確率収束することとあります。
以下の手書きメモにあるように、チェビシェフの不等式を使って導出できることがわかります。
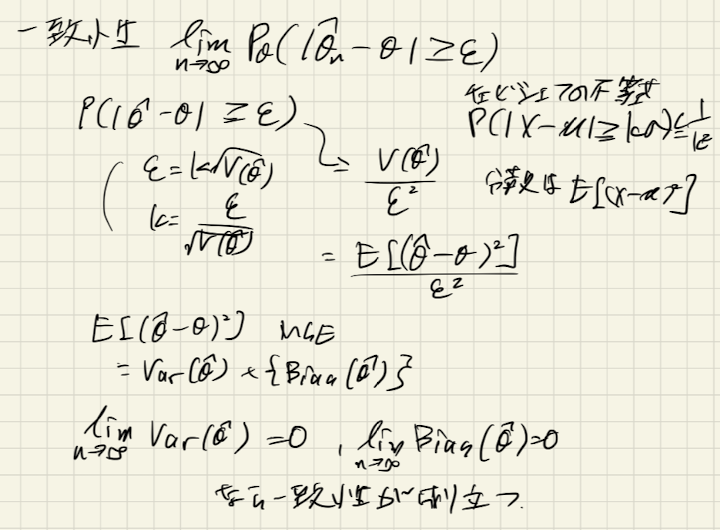
漸近有効性(asymptotic efficiency)
漸近有効性については、用語を整理するだけです(正直理解できてないところです)。
「有効推定量」というのは前回の議論で出てきましたが、分散がクラメール・ラオ下限な不偏分散でした。
「漸近」有効性ということで、漸近的な分散がクラメール・ラオの下限を示すというのが「漸近有効性」です。
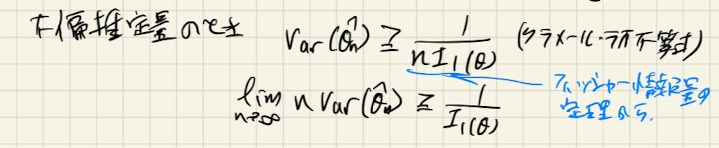
おまけ:分散の不偏性
これだけだと寂しいので、不偏分散の導出をおまけとしてまとめます。
分散といったら標本分散がよく使われていますが(最尤推定量ですし)、前回標本分散にはバイアスがあるということを述べました。そのため、不偏分散と比較していましたが、この不偏分散はなぜあの式なのかを証明してみます。
例によって手書きなので読みにくいと思いますが、やっていることはシンプルです。まず、標本分散の期待値を計算します。この期待値から、真の分散が期待値になるにはどうしたら良いかを考えます。
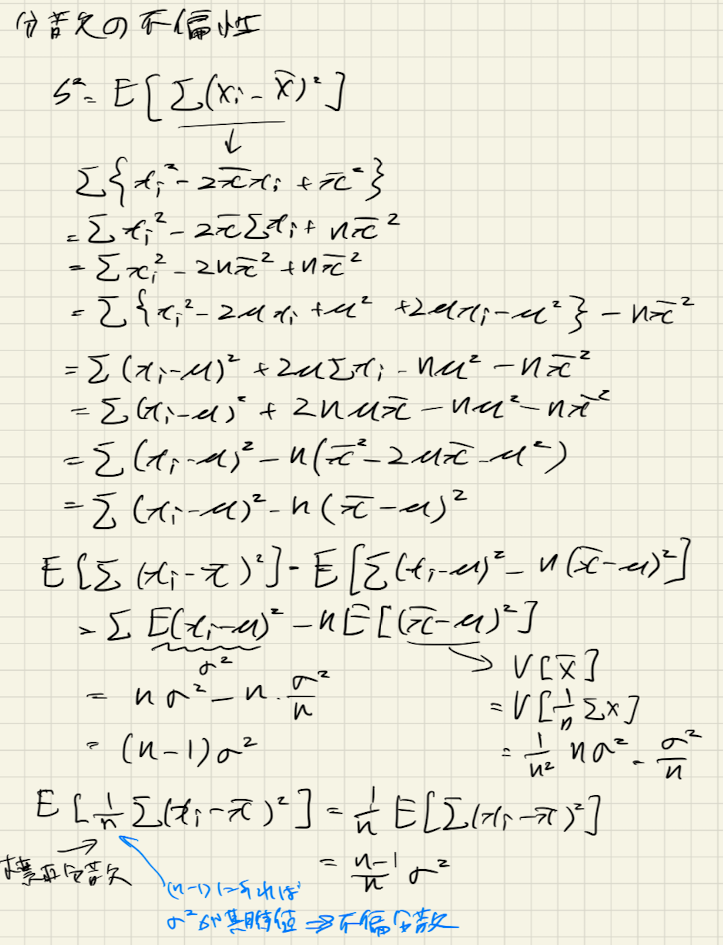
参考資料
[1] 日本統計学会, 統計学実践ワークブック, 2020, 学術図書出版社
日本統計学会公式認定 統計検定準1級対応 統計学実践ワークブック
- 発売日: 2020/05/29
- メディア: 単行本
- 発売日: 1991/07/09
- メディア: 単行本
[3] 矢島ら, 自然科学の統計学, 1992, 東京大学出版会
- 発売日: 1992/08/01
- メディア: 単行本
[4] 久保川, 現代数理統計学の基礎, 2017, 共立出版
- 作者:達也, 久保川
- 発売日: 2017/04/07
- メディア: 単行本
[5] 竹村, 現代数理統計学, 2021, 学術図書出版社
- 作者:彰通, 竹村
- 発売日: 2020/11/10
- メディア: 単行本
【統計検定準一級】第8章 統計的推定の基礎 #3【番外編】
【概要】
【目次】
はじめに
「統計学実践ワークブック(参考資料1)」の問題を解いていくシリーズをやっていく中で、8章「統計的推定の基礎」の内容をさっぱり理解していないことがわかったので、改めて整理しています。
参考にした資料は参考文献に列挙しています。中でも主に文献4を参考にしています。
心優しい方、間違いに気付いたら優しく教えてください。
8章の流れ
統計の目的の一つとして、「未知パラメータの推定」という問題があり、この章ではその中でも「点推定」について扱っています*1。「区間推定」については9章で扱われています。
- 情報の集約
- 推論を行うにあたって、生データを全て保存するのではなく、情報を集約できればうれしい(メモリ的に)
- → 「十分統計量」
- 推定法
- パラメータの点推定を行うためにはいくつか方法がある
- → モーメント法
- → 最尤推定
- 推定量の評価、推定量の性質
この流れに沿って、確認内容をまとめていこうと思います。
今回は、推定量を評価する基準として「不偏性」という性質を扱います。
推定量の性質
前回は、パラメトリックなモデルにおけるパラメータの推論方法として、「モーメント法」と「最尤法」を扱いました。
パラメータの推論方法は他にも事後確率最大化法(MAP推定)などの方法がありますが、それらの推定量の性質を評価して、どのような推定量が好ましいのかを議論していきます。
不偏性
推定量は、データによって結果が変わるので確率変数です。確率変数なので、なんらかのばらつきを持っています。
この推定量が有していて欲しい性質として、真のパラメータ
の周辺にばらついて欲しいということがあります*3。データから推定したいのは真のパラメータ
であり、全然別の所に推定量のピークが立っていても全然嬉しくないですからね。
さらに、推定量が
を中心にしていても大きくばらついていたらうれしくないです。
ということで、推定量の期待値と分散を評価するのが、推定量の評価基準として第一に挙げられます。以下の手書きメモのように、
の期待値が
と一致する推定量を「不偏推定量(unbiased estimator)」と定義されています。
また、の期待値と
の差を「バイアス(bias)」と呼びます。

平均二乗誤差(MLE; Mean Squared Error)
ということで、バイアスと分散が小さくなる推定量だとうれしいです。
バイアスと分散を合わせて評価する指標として平均二乗誤差(MLE; Mean Squared Error)があります。平均二乗誤差自体はよく使われる指標ですけど、バイアスと分散を1:1で評価する指標という意味があったんですね。

不偏分散と標本分散(最尤推移定量)を比較する
分散の推定量として、不偏分散[tex:V2]と標本分散[tex:S2]があります。とくに、標本分散は前回取り上げた最尤推定の結果として得られているもので、よく使われます。一方不偏分散は、上記の不偏性で触れたようにバイアスが0の推定量です*4。
どっちが好ましい推定量でしょうか?というのを確認してみます。参考文献[4]に記載の例題なので、詳しくはそちらを。
ここでは、サンプルは正規分布に従って独立に得られているとします。
まず、Qという量を定義しています。これは、カイ二乗分布に従う性質があることがわかっています*5。

カイ二乗分布に従う確率変数の期待値と分散の性質*6から、バイアス、分散が計算でき、これらを合わせてMSEを求めることができます。

実際に不偏分散と標本分散について、バイアス、分散、MSEを比較した結果、標本分散は分散とMSEが小さくなることがわかりました。

この結果から、標本分散の方が望ましいといって良いかは微妙なところです。推定量は真のパラメータとずれたところにピークが出ている可能性があるということなので。
分散はどこまで小さくできる?>クラーメル・ラオの不等式
不偏推定量はバイアスが0なので、分散が小さいほど良い推定量です。
この分散がどこまで小さくできるのか?という疑問がわきますが、この分散の下限は計算することができるようです。この下限をクラーメル・ラオの下限と呼んでいるようです。
この下限ですが、フィッシャー情報量の逆数で定義されるとのことです。フィッシャー情報量は以下のメモに記載のように、対数尤度の勾配の期待値となっています。勾配が鋭いほど分散が小さいということですし、データが多くなる程推定量の分散は小さくなっていきます。

正規母集団を例にしてクラーメル・ラオの下限を計算してみる
(これも詳しくは参考文献[4]を参照してください)
分散1として、平均パラメータμが未知の正規母集団に従う確率変数Xを考えます。 実際の計算は参考文献[4]に記載のフィッシャー情報量の3つの性質を使って容易に導出することができます(命題の証明は追ってない。。。)。

有効推定量とは?
参考文献[1]に書かれていますが、クラーメル・ラオの不等式の下限となる不偏推定量のことを「有効推定量(efficient estimator)」と呼ぶらしいです。
分散が最小の不偏推定量(=バイアスが0)なので、この推定量が最も良い推定量ということになります。
参考資料
[1] 日本統計学会, 統計学実践ワークブック, 2020, 学術図書出版社
日本統計学会公式認定 統計検定準1級対応 統計学実践ワークブック
- 発売日: 2020/05/29
- メディア: 単行本
- 発売日: 1991/07/09
- メディア: 単行本
[3] 矢島ら, 自然科学の統計学, 1992, 東京大学出版会
- 発売日: 1992/08/01
- メディア: 単行本
[4] 久保川, 現代数理統計学の基礎, 2017, 共立出版
- 作者:達也, 久保川
- 発売日: 2017/04/07
- メディア: 単行本
[5] 竹村, 現代数理統計学, 2021, 学術図書出版社
- 作者:彰通, 竹村
- 発売日: 2020/11/10
- メディア: 単行本