【輪読会メモ】深層学習による自然言語処理#4
【概要】
- 「深層学習による自然言語処理」の輪読会をしています
- 輪読会第4回目は5章が範囲でした
【目次】
はじめに
講談社MLPシリーズの「深層学習による自然言語処理」の輪読会をしています。 輪読会の範囲で気になったことや資料のリンクなどをまとめていきます。
輪読会のリンクはこちらです。
「深層学習による自然言語処理」のほか、輪読会を定期開催しているので、気になった方はグループメンバーになってもらえるとうれしいです。 また、Slackのwork groupを用意しているので、参加したい方は何らかの方法で私に連絡ください(輪読会参加してなくてもwelcome)。
輪読会記録
資料リンク
勉強会で利用した資料のリンクを貼ります。いつも通り発表担当は私でした。 なお、輪読会中に書き込んだメモなどがそのまま残っているので、一部見づらい箇所があるかもしれません。。。
第5章の概要
5章は章題が「応用」というだけあって、具体的な4つの応用課題についてモデルの例と課題に対しての難しさや課題について書かれていました。ただ、書籍内にも書かれていますが、2017年初版の本なので現在(2022年)からすると内容的にはちょっと古いものもあると思います。
紹介されている応用課題は「機械翻訳」、「文書要約」、「対話」、「質問応答」の4つです。それぞれの応用課題については書籍か上記に添付の資料を参照いただけたらと。
5章全体を通した感想
翻訳課題については、問題設定がはっきりしていることから、学習データを集めやすいということでした。
一方その他のタスクについて、一貫して課題として挙げられているのは「評価指標」の難しさということでした。これは「問題設定の曖昧さ」に起因すると思われますが。
例えば文書要約については、「要約文」について要約の長さについての規定みたいなものはなくて、実際の利用現場でどのような「要約文」が必要なのかに依存するわけです。これは、実は私も以前業務で突き当たった問題でした。
そこで、性能を評価するためのタスク設定が色々行われているわけですが、作られた問題設定なので、どうしても箱庭感が抜けないような気がします。利用者は、こういった課題を踏まえて、自分自身が直面している課題にどうやってアプローチするかを考えていかないといけないんですよね。
その他:キャッチアップについて
本書については、2017年初版ということで5年前の情報までがまとまっているものになります。自然言語処理に限定されず、深層学習の分野は日進月歩のようなので、すでに情報が古いという指摘もあります。この点を踏まえて、「最新のモデルをどのようにキャッチアップしていくか」という議論になりました。
色々な意見があると思いますし、立場によっても異なってくると思います。私は研究者ではなく利用者の立場なのですが、「最新の情報をキャッチアップできてないからといって焦らない」と考えています。また、「最新のモデル」を追うよりも分野が扱っている「課題」とベーシックな仕組みを知っておくことが重要だと考えています。
なぜなら、評価指標となるスコアは条件によって大きく変動することがままあります(乱数シードみたいなものなどでも)。また、スコアを計算する元になる課題設定が実際に直面している課題とフィットするとは限らないためです。
情報収集については私自身うまくできてない感じはするのですが、基本的な考え方としてこのように回答しました。
その他:実務での利用について
上記と関連するのですが、実務で利用する際の考え方についても議論となりました。
私は、初手として「枯れた技術」を利用することが良いと考えています。
上記で挙げたように、論文用の課題設定に過剰にフィットしている可能性もあるので、まずはベーシックな仕組みを試すことが重要と思っています。
おわりに
ということで、「深層学習による自然言語処理」輪読会第4回目の記録でした。
今回は応用タスクについて眺めました。応用タスクの多くで「評価」指標が課題になっているということで、まぁそういう問題よなと改めて感じた次第です。そういった意味で、自然言語を扱うのは難しいなと感じました。
次回は最終回。
参考文献
")
【輪読会メモ】深層学習による自然言語処理#3
【概要】
- 「深層学習による自然言語処理」の輪読会をしています
- 輪読会第3回目は4章が範囲でした
【目次】
はじめに
講談社MLPシリーズの「深層学習による自然言語処理」の輪読会をしています。 輪読会の範囲で気になったことや資料のリンクなどをまとめていきます。
輪読会のリンクはこちらです。
「深層学習による自然言語処理」のほか、輪読会を定期開催しているので、気になった方はグループメンバーになってもらえるとうれしいです。 また、Slackのwork groupを用意しているので、参加したい方は何らかの方法で私に連絡ください(輪読会参加してなくてもwelcome)。
輪読会記録
資料リンク
勉強会で利用した資料のリンクを貼ります。発表担当は私でした。 なお、輪読会中に書き込んだメモなどがそのまま残っているので、一部見づらい箇所があるかもしれません。。。
第4章の概要
4章では、深層学習ベースの自然言語処理に特有の工夫が3点解説されています。
3点というのは、「注意機構(Attention mechanism)」、「記憶ネットワーク(momory network)」、「出力層の高速化」です。今現在では、Attention機構を利用したモデルが高い精度を叩き出している状況です。Attentionを利用するというのがデファクトスタンダードになりつつあるのかなと思います。
注意機構
注意機構(attention mechanism)をざっくりと表現すると、出力の生成時に必要な入力情報の重みを含めて学習する仕組みということになります。
通常の系列変換モデルが入力情報を全て一つのベクトルにEncodeしていることから、長い系列を扱うのは現実的に難しそうな感じがするという問題に対してのアプローチとなっているようです。わかりやすいかどうかは置いておいて、上記のスライドで図解しようと努力した跡が残っているのでよければ見てもらえればと思います。
注意機構という仕組みを導入していることでネットワークが複雑になっているように見えますが、結局のところ足し合わせる関数が一つ増えたと見れば、全てまとめて合成関数の微分を利用して勾配を計算できそうだなと理解できます(導出はしていないですが)。全てをニューラルネットワークで表現できるように行列積で表現できるというポイントを押さえておくと、怖く感じないような気がしました。
記憶ネットワーク
記憶ネットワークとは、記憶情報(文書をベクトル化したもの)を保持しておき、出力の生成時に必要な記憶情報の重みを含めて学習する仕組みということになります。書籍では、「直接的に記憶の仕組みをモデル化する研究の一つ」と書かれています。
注意機構とかなり似ている表現をあえてしたのですが、結局end-to-endに学習するモデルは、注意機構と同じような構成になるようです。
出力層の高速化
特に文書生成問題は語彙集合の中から単語を一つ選択する問題、つまり巨大な分類問題となります。そこで出てくるのが巨大なsoftmax関数なのですが、巨大なsoftmax関数の計算量を少なくするためのアプローチについて紹介がされています。
以下の3つの分類に分かれるのかなと思っています。
- 近似計算(少数のサンプルだけを使って計算):重点サンプリング
- 確率モデルを別の形に変形: NCE、負例サンプリング、ブラックアウト
- ソフトマックス関数を小さなソフトマックス関数の積でおきかえる:階層的ソフトマックス
その他:語彙の削減について
「出力層の高速化」では、語彙が多くなることで生じる問題をどう解決するかという取り組みでした。輪読会の議論の中で、「そもそも語彙を小さくすることで高速化の問題をクリアするという考えもあるよね」という話題になり、以下の文献を紹介してもらいました。
トークナイズフリーなモデルというのが最近出てきているという話は聞いていたのですが、そういったアプローチの一つです。
おわりに
ということで、「深層学習による自然言語処理」輪読会第3回目の記録でした。
4章では、今現在多く利用されている「注意機構」を扱いました。仕組み自体は気持ちを理解すると自然な構成でわかりやすく、また効果もあるだろうなということが理解できるかなと思います。
私の個人的なモチベーションとして、注意機構を理解したいというのが大きくありましたので、その仕組みを理解できたので満足です。
次回も楽しみ
参考文献
【輪読会メモ】深層学習による自然言語処理#1
【概要】
- 「深層学習による自然言語処理」の輪読会をしています
- 輪読会第1回目は1,2章が範囲でした
【目次】
はじめに
講談社MLPシリーズの「深層学習による自然言語処理」の輪読会をしています。 輪読会の範囲で気になったことや資料のリンクなどをまとめていきます。
輪読会のリンクはこちらです。
「深層学習による自然言語処理」のほか、輪読会を定期開催しているので、気になった方はグループメンバーになってもらえるとうれしいです。 また、Slackのwork groupを用意しているので、参加したい方は何かの方法で私に連絡ください(輪読会参加してなくてもwelcome)。
輪読会記録
資料リンク
勉強会で利用した資料のリンクを貼ります。発表担当は私でした。 なお、輪読会中に書き込んだメモなどがそのまま残っているので、一部見づらい箇所があるかもしれません。。。
第1章の概要
第1章は全体のintroductionとして、自然言語処理研究における深層学習への期待といったことが書かれていました。 この章で重要と思ったのは、「テキストデータ」とは何か?ということで、「可変長」の「記号」列であるということです。
記号の列ということで、i.i.d.仮定が成り立たない、つまり、「系列データ」として扱う必要があるということです。これは、3章で「言語モデル」で確率モデルとしての定式化がされています。
次に「可変長」であることで、記号の組み合わせが無限に存在する、つまり、文の最適な確率モデルを導出できないということになります。
こういった課題への対応として、深層学習による柔軟なモデルを適用していこうという流れということですね。
第2章の概要
第2章は、「ニューラルネットワークの基礎」ということで、代表的なNNの構造、学習方法としての勾配法(からの誤差逆伝播法)などが簡潔にまとめられていました。
系列データを前提として書かれており、シンプルな例で説明が展開されているので、とてもわかりやすいと思います。
輪読会の中でも議論になりましたが、さまざまなモデル(CNN、RNNなど)が行列演算で完結に表現するとどのような表現になるのかが明示的に記載されています。これがすごくわかりやすかったです。 行列演算として理解することで、自動微分についても理解が進みます。
ただ、尤度の最大化(損失関数が負の対数尤度)という言及が何度もされていましたが、確率モデルとしてどのようなモデルを仮定するのかについての言及がないので、「尤度を最大化」と書かれても、尤度関数どこから持ってきた?という疑問が湧いてくるんじゃないかなと思いました。
多クラス分類モデルであるなら、カテゴリ分布とソフトマックス関数について説明があるとよりわかりやすいのかなと思いました。
おわりに
ということで、「深層学習による自然言語処理」輪読会第1回目の記録でした。
参加者からも、この書籍は非常にわかりやすいと評判でしたので、今後も楽しみです。
参考文献
【輪読会メモ】深層学習による自然言語処理#2
【概要】
- 「深層学習による自然言語処理」の輪読会をしています
- 輪読会第2回目は3章の「言語処理における深層学習の基礎」
【目次】
はじめに
講談社MLPシリーズの「深層学習による自然言語処理」の輪読会をしています。 輪読会の範囲で気になったことや資料のリンクなどをまとめていきます。
輪読会のリンクはこちらです。
輪読会を定期開催しているので、気になった方はグループメンバーになってもらえるとうれしいです。 また、Slackのwork groupを用意しているので、参加したい方は何かの方法で私に連絡ください。
輪読会記録
資料リンク
勉強会で利用した資料のリンクを貼ります。発表担当は私でした。 なお、輪読会中に書き込んだメモなどがそのまま残っているので、一部見づらい箇所があるかもしれません。。。
第3章の概要
第3章では、言語モデルとはどんなものか?深層学習における言語モデル(ニューラル言語モデル)にはどんな種類があるのか?について主に書かれていました。
「言語モデル」とは、文が生成される確率のモデルということで、その定式化は系列データの確率モデルと同じです(下式、テキストp49, 式3.5)。

この確率計算をニューラルネットでやるというのが「ニューラル言語モデル」と書かれていました。 確率は語彙集合に含まれる各単語の確率、つまり離散分布なので、多クラスロジスティック回帰と捉えるとわかりやすいのかなと思いました。
こう捉えると、順伝播NNもRNNも結局は行列とベクトルの演算が連なったもの(2章)なので、なじみが出てきますね。
順伝播NN言語モデル(FFNNLM)は順番を意識するのか?
これは、輪読会中に出てきた議論の一つです。 FFNNLMでは、入力ベクトルを単純にconcatしてNNに入れていると理解していますが、このように固めたベクトルを入れて、「単語」の「順番」が学習に影響するのか?という議論だったと記憶しています。
私の理解では、「順番」については順番に意味があれば(直近の単語に強く影響するなど)、それを汲んでパラメータ行列が学習されるので「順番」は意識されるだろうと理解しています。 ただ、入力ベクトルをconcatしているので、それぞれの「単語」という区切りが明らかでない状態になっているので、文脈が活用されるのか不思議な感じをもっています。
NNは、人間による解釈を意識しないので、何かうまいこと学習してくれるのかもしれませんが、不思議というかほんのりと気持ち悪さを感じているところです。。。
系列変換モデルはRNN言語モデルの初期値問題
3.4節ではSeq2Seqが扱われていましたが、「RNN言語モデルの初期状態をエンコーダーの隠れ状態とする」というだけのモデルだと書かれていました。 個人的にseq2seqは論文読んでもいまいち理解ができてない感じがしていたのですが、この表現はすごくわかりやすいと思います。
そうすると、単純な系列変換モデルでは、エンコーダの最初の方の入力情報が複合化器に伝播してくるまでにだいぶ情報が損失してしまっているだろうなと想像できます。LSTMなど長期の記憶を意識したユニットでは、途中で情報がリセットされてしまうこともあるのでなおさらではないかなと。 ここから、4章のAttention機構につながっていくという自然な流れができると理解できますね。
やはり基礎を学習するのは重要ですね。
おわりに
ということで、輪読会第2回目の記録でした。
個人的には、系列変換モデルの気持ちが理解できた気がしてよかったです。 あと、発表資料のp.6の図がよくできたと思うので是非見て欲しいです。
参考文献
Juliaを使ってギブスサンプリングで線形回帰(多項式回帰)する
【概要】
【目次】
はじめに
良い良いとすごく評判のJulia言語を触ってみました。
ここでは、Juliaの練習として、線形回帰(多項式回帰)をベイズ的に推論する「ベイズ線形回帰モデル」の推論をやってみます。 ベイズ線形回帰の推論は、行列演算、制御構文(ループ)、描画あたりが全て含まれていて良い題材と思います。
また、私が普段使っているプログラミング言語であるPythonとの比較として、(厳密ではないですが)計算速度の定量的な比較と、使ってみた感想を定性的な比較として列挙してみます。
間違いなどあったら指摘していただけると助かります。
実験環境
実験環境はMac mini (Apple M1チップ)でJupyter labで書いています。環境構築について詳しくは私の書いた以下のQiita記事を見てください。
線形回帰モデル
線形回帰モデルは、入力ベクトルと重みベクトル
の線型結合で目的変数
を表現するモデルです。
当ブログでは、線形回帰モデルについては何度か扱っていますので、モデルの詳細については以下の記事などを合わせて参照していただけたらと思います。
learning-with-machine.hatenablog.com
では、今回扱うモデルを定義していきます。
システムモデル
今回は、システムノイズはないとして、以下の通り入力ベクトルと重みベクトル
の線型結合とします。
![]()
ここで、入力ベクトルは以下の通り、k次の冪乗を特徴量としています。
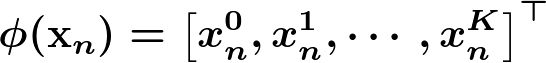
観測モデル
上記のシステムモデルに対して、観測時にはガウスノイズが乗ってくるとします。
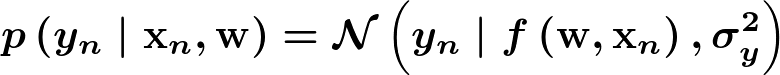
ここで、観測ノイズの分散は既知のパラメータとします。
重みベクトルの事前分布
重みベクトルの事前分布は、以下の通り各次元独立な多変量ガウス分布とします。
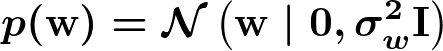
同時分布
ということで全体を結合して、今回推論するモデルは以下の通りです。
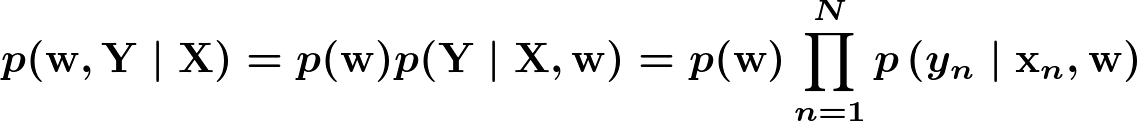
モデルの推論
線形回帰モデルは重みベクトルの事前分布にガウス分布を利用すれば解析的に解を導出できます。
ですが、プログラミングの練習として、ここではギブスサンプリングによる近似解も合わせて計算します。
解析解
複数の観測データを使って上記モデルを推論した結果としての重みベクトルの事後分布
は以下の記事にあるように導出できます。(以下の記事では手書きで導出過程を書いています。汚い手書きでごめんなさい)
learning-with-machine.hatenablog.com
近似解(Gibbs sampling)
MCMCアルゴリズム(ギブスサンプリング)を利用して近似解も推論してみます。
今回は、単変量ガウス分布からのサンプルは容易だが、多変量ガウス分布からのサンプルは難しいと仮定して、の各次元について独立にサンプルすることにします。
i次元の重みのサンプルを取得するにはi次元以外の重み
を固定とした条件付き分布を導出する必要がありますが、その導出については以下の記事に導出過程を掲載しています。(これも汚い手書きでごめんなさい)
learning-with-machine.hatenablog.com
実装
トイデータ
今回扱うトイデータは、3次の多項式に従う以下の関数(オレンジ線)からサンプルします。サンプルしたデータは青点で描画しています。
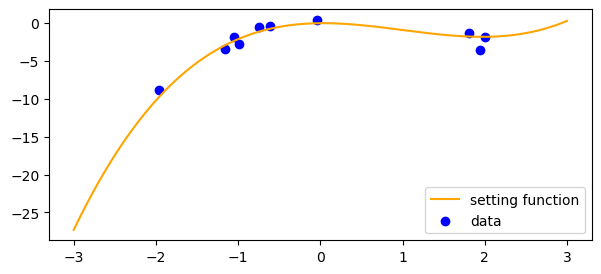
実装で詰まったところ
Distributions.jlのMvNormalを利用して多変量ガウス分布に従う乱数を生成するところで、解析的に算出した共分散行列を入力したら以下のエラーが出てしまいました。
ERROR: PosDefException: matrix is not Hermitian; Cholesky factorization failed.
ここの議論でSymmetric関数を通せば良いということは分かったのですが、Symmetric関数を通しても(通す前と)行列の各値は同じように見えますし。。。エルミート行列とか全然理解していないので、よく分からず対応したままです。
推論結果
推論に利用したコードは以下のリンクを参照してください。
Juliaでの実装 → gibbs_sampling_regression_julia.ipynb · GitHub
Pythonでの実装 → gibbs_sampling_regression_python.ipynb · GitHub
推論したの事後分布
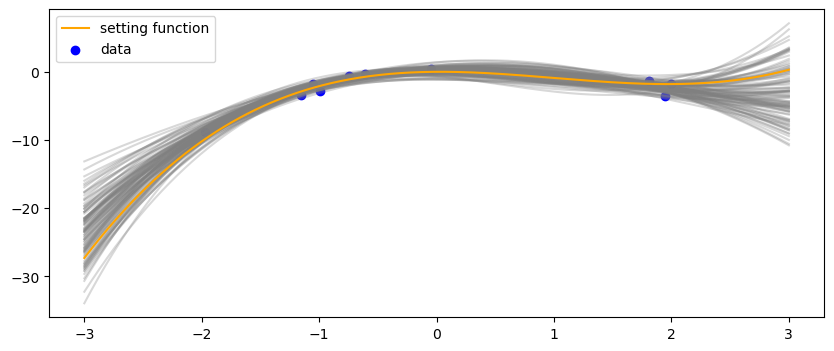
に基づいて関数を100本サンプルして上記のトイデータのグラフに重ねた結果は以下の通りです。
まずは解析解
こちらは近似解
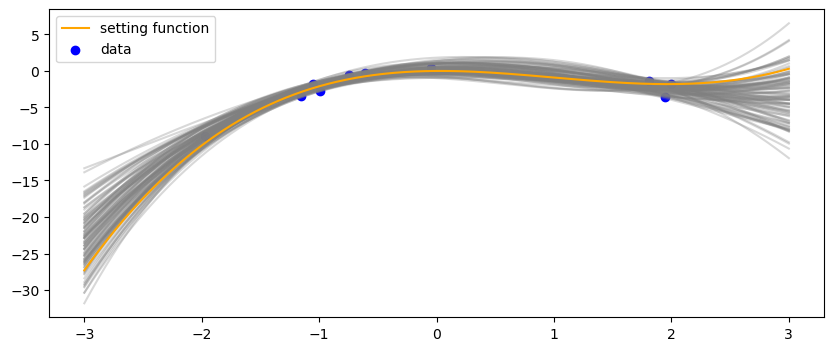
解析解と近似解は(当然ですが)同じような結果になってくれました。上記のリンク先のnotebooにはの分布も合わせて掲載しており、それを見ても同じような結果になっていることが分かります。
データが少ないところは、関数のバリエーションが広がっているということが分かります。なお、これは予測分布ではないので注意です。
Pythonとの比較
計算速度の比較。
| 解析解[sec] | ギブスサンプリング 10,000サンプル[sec] | |
|---|---|---|
| Python | 0.021 | 6.91 |
| Julia(コンパイル込み) | 6.27 | 2.10 |
| Julia(コンパイル無し) | 0.0003 | 0.40 |
「コンパイル込み」とは、Jupyterで最初に関数を実行した際の計算時間です。「コンパイル無し」とは、2度目に実行した結果です。(という理解であっているんでしょうか??)
訂正的な比較。
- Juliaはmatlabぽい
- 公式ページにも書いてある
- 行列演算が直接書けるので、数式を比較的そのまま書ける気がする
Pythonの方が仕事でも何年も使っているので当然すんなり書けるのですが、Juliaは数式に近い形でコードを書けるような気がするので、書きやすいかもなーという感じはしました。が、正直Juliaはまだよくわかってないです。
最適化の余地はまだまだあるのでしょうけど、ループが入るような計算は期待通りJuliaがだいぶ速そうです。これは仕事でもJuliaを推していった方が良いかも。
ただ、繰り返しが入らないような単発の処理についてだけ見ると、Pythonの方が処理は速く終わりました。コンパイルしてるからなんでしょうけど。ほんとに単発でしか実行しない処理なら別ですが、パラメータを変えて何度か試すような場合などJuliaで事前にコンパイルしておくと、この点も解消されるのかなと思いました。
おわりに
ということで、Juliaを使って線形回帰モデルを書いてみました。
最適化の余地はどちらもあると思いますが、同程度に雑に書いたJuliaコードとPythonコードの計算時間を比較すると、 forループを使うような処理の場合はコンパイル時間含めてもJuliaの方が速そうでした。ものに依るのでしょうけど。 速度以外にも、Juliaでは行列演算が素直に書けるの良さそうに感じました(matlabみたい)。
参考文献
")

【統計検定準一級】統計学実践ワークブックの問題をゆるゆると解く#28
【概要】
【目次】
はじめに
本シリーズでは、いろいろあってリハビリも兼ねて統計学実践ワークブックの問題を解いていきます。 統計検定を受けるかどうかは置いておいて。
今回は13章「ノンパラメトリック法」から1問。
なお、問題の全文などは著作権の問題があるかと思って掲載してないです。わかりにくくてすまんですが、自分用なので。
心優しい方、間違いに気付いたら優しく教えてください。
問13.1
問題
血圧を下げる薬剤AとBがある。Aの方が新規で開発したもので、Bよりも効果が高いことが期待されている。
ということで、帰無仮説と対立仮説として以下のものを検定していきたいということになります。
(1) 6人の患者をランダムに3:3に分けてA, Bを投与。順位和検定における片側P-値はいくらか?
データについては以下のメモを参照ください。
検定というのは、ある仮定(基本的には帰無仮説)に基づいているとしたときに、手元のデータが発生する確率は大きいのか小さいのかを議論する枠組みです。確率がすごく小さいなら、仮定が間違っている、つまり帰無仮説が棄却される、ということになります。
本章で扱うノンパラメトリック法も同様で、効果が同じであると仮定するなら、順位などはランダムに生じるはずと考え、実際のデータがどの程度ずれているのかを議論します。
ということで本問題については、A, Bの各群の順位の和がランダムに生じているとするなら確率はいくらかというのを計算します。今回のデータでは、A群の順位和が7であり、和が7以下になる組み合わせは二通りしかありません。全体の組み合わせすうは20通りとなるので、結局10%ということがわかります。

(2) 別に被験者を募って順位和検定を行ったところ、片側P-値が3%未満になった。この場合、最低何人の被験者がいたか?
(1)の手順を思い起こすと、P-値は「対象の組み合わせ数」/「全体の組み合わせ数」です。”最低何人”の被験者が必要かという問なので、対象となる組み合わせ数は1が最小の数となります。
人数が6人の場合、組み合わせ数は20通りが最大です。3:3に分ける以外の組み合わせ数は20よりも小さくなることは、実際に計算しても容易にわかりますし、エントロピーを考えてもわかります。ということで6人の場合は5%が最小となります。
というのを他の人数で試していけばよく、結局、7人が最小人数であることがわかります。

(3) 患者3人にA, Bを投与し血圧値の差を比較した。符号付き順位検定を行う場合の片側P-値はいくらか?
これも順位和検定と同じような考え方の検定ですね。帰無仮説が正しいならば、符号はランダムになるはずだが、それとどの程度のずれがあるのかを評価しています。
今回のデータの場合(以下のメモのDを参照)、被験者は3人なので、1~3に符号がつくパターンは8通り、今回は順位の和が5なので、5以上となる組み合わせは2。ということで25%ということがわかりました。

(4) (3)と同様の検定を別の被験者を募って実施したところP-値が5%未満になった。この時最低でも何人の被験者がいたか?
やり方は(2)と全く同じです。
n=3, 4,,,, と評価していきます。

参考資料

【統計検定準一級】統計学実践ワークブックの問題をゆるゆると解く#27
【概要】
- 統計検定準一級対応 統計学実践ワークブックの問題を解いていくシリーズ
- 第27回は12章「一般の分布に関する検定」から3問
【目次】
はじめに
本シリーズでは、いろいろあってリハビリも兼ねて統計学実践ワークブックの問題を解いていきます。 統計検定を受けるかどうかは置いておいて。
今回は12章「一般の分布に関する検定」から3問。
なお、問題の全文などは著作権の問題があるかと思って掲載してないです。わかりにくくてすまんですが、自分用なので。
心優しい方、間違いに気付いたら優しく教えてください。
問12.1
問題
ある小売店に対する、一週間分の「お問い合わせ」の回数の調査結果の表がある(ここでは表は掲載しません)。この調査結果に基づいて、曜日によって問い合わせ回数に差があるのかを考えたい。
一様性の検定を有意水準5%で行いたい。
(1) この検定を行うためのカイ二乗統計量を求めよ
適合度検定を行います。この時の検定統計量はテキストに書かれている通りです。以下の手書きメモなどを参考にしてください。

(2) 棄却限界値を求め、検定結果を求めよ
統計量はカイ二乗分布に従うので、自由度を考える必要があります。この場合、一週間(7)に対して自由に動けるパラメータは6となります(自由度=6)。
そのため、分布表から5%有意水準だと12.59であることがわかります(棄却限界値)。
ということで、[検定統計量 > 棄却限界値] なので、帰無仮説は棄却されることになります。結果として、曜日毎の回数は異なるといえます。
問12.2
この問題は、論述問題でテキストの回答を見ればよく理解できると思います。一応私なりの回答(抜粋)を記載しますが、テキストの方を参照された方が良いと思います。
問題
(この問題も表が出てきますが、ここには掲載しません)
1年間の台風上陸回数を69年間に渡って調査した結果、平均2.99回、標準偏差は1.70回だった。
(1) この結果から、台風の上陸回数はポアソン分布に従うのではないかととの意見が出た。この意見の意味するところは何か?
上陸回数がポアソン分布に従うとすると、ポアソン分布の期待値と分散は同じです。

平均と分散が近い値になっているので、「ポアソン分布」に従うのではないか?との意見が出たということです。
(2) 台風上陸数がポアソン分布に従うと仮定した場合の期待度数の求め方を示せ
ポアソン分布の定義に従ってx回上陸する確率を導出します。合計で69なので、この確率に69を掛け合わせたものが期待度数となります。
(これはテキストの方が詳しいのでそちらを参照してください)
(3) カイ二乗統計量を導出した結果16.37となった。適合度検定を有意水準5%で行った時の結果について論ぜよ。
自由度はカテゴリ数が0回から10回までの11種類あります。また、パラメータとしてポアソン分布のパラメータが一つあるので、となります。
棄却限界値は、分布表から16.92であることがわかりますので、この検定結果は帰無仮説が棄却されます。
帰無仮説は棄却されましたが、検定統計量は棄却限界値に近い値となりました。統計量が大きくなってしまった理由として、上陸回数が「10以上」のカテゴリは期待度数が非常に小さい(確率が小さい)のにここの度数が1となってしまったことが挙げられます。
(4) 上陸回数を6回以上をまとめるようにカテゴリを変更した場合の検定結果と当てはまりの良さについて論ぜよ
6回以上をカテゴリとしてまとめると、以下のメモのようになり、検定統計量は小さくなりました。

問12.3
問題
Instagramの男女別の利用者数の調査を行ったクロス集計表があります(これも表自体は掲載しません)。
男女での利用率に差があるのかを比較するために、有意水準5%で検定を行う
検定の設定として以下のメモの通りとなります。

ここでは比率の差()がある(対立仮説)のかない(帰無仮説)のかを検定で確認します。
利用者か否かは、確率で利用するかしないかが決まるベルヌーイ過程であると考えます。また、男女での利用者数の割合はそれぞれの比率
にのみ従い、男女間の利用者数はそれぞれ独立と仮定します。
するとそこから、中心極限定理を利用して以下のメモの通り標準正規分布に従う量を導出することができます。

この量から、帰無仮説の元での統計量は自ずと導出できます(以下のメモ参照)。ということで、あとはこの統計量に具体的に数値を当てはめていけば良いです。

テキストでの回答は、ここからさらに統計量の分母について最尤推定量を利用すると書かれています。しかし、どちらでも良いとも書かれていますし、上記メモの方がわかりやすいと思うので、ここまでとします。
")