変分推論による近似ベイズ推論
【概要】
【目次】
はじめに
ベイズ推論についての書籍を読んでいると、なんとなく理解はできても具体的なイメージがわかないことないですか?
ということで、実装して理解を深めていきたいと思います。
本記事ではベイズ推論における近似推論について扱います。 ベイズ推論では「MCMC(Markov Chain Monte Carlo)法」などのサンプリングに基づくアルゴリズムと「変分推論」という代表的な近似推論手法があります。
サンプリングに基づく近似ベイズ推論(MCMC)について、過去3回に分けて書いてきました。 その1では、基本的な積分の近似計算である「モンテカルロ積分」と最も単純なサンプリングアルゴリズムである「棄却サンプリング」を実装しました。 その2では、MCMCアルゴリズムの一種である「メトロポリス法」を実装しました。 その3では、同じくMCMCアルゴリズムの一種であるギブスサンプリングを実装してみました。
今回は、サンプリングをベースとした近似アルゴリズムとは異なる、平均場近似を使った変分推論を実装してみます。
本記事は、「ベイズ深層学習」の「4章 近似ベイズ推論」を参考にしています。
")
- 作者:須山 敦志
- 発売日: 2019/08/08
- メディア: 単行本
間違いなどあったら指摘していただけると助かります。
変分推論
ベイズ推論において、パラメータの推論が解析的に行えないケースがあります。例えば、確率変数が非線形な関係にあるとか、確率変数同士が共役関係にないなどの場合です。このような場合には近似的に推論を行う必要があります。
ベイズ推論でよく使われる近似推論手法として、大きく分けて以下の二つの手法があります。
- MCMC:サンプリングに基づく推論
- 変分推論:最適化に基づく推論
ここでは変分推論によって近似ベイズ推論を実装してみようと思います。
変分推論による近似ベイズ推論
変分推論の詳細は、PRML(下)やベイズ深層学習などを参照ください*1。
長くなってしまったので詳細はクリックで展開
観測変数を、潜在変数を
とすると、モデルは
となります。ベイズ推論では、データ
に基づいて潜在変数
の事後分布
を求めることが目的です。
ここでは事後分布が解析的に求められない場合を考えます。そこで、事後分布
を素性のわかっている関数
で近似することを考えます。
と
が近い(近似できている)とする指標として、KLダイバージェンス(Kullback-Leibler Divergence)を使います。
このKLダイバージェンスを最小化するようにを求めれば良いのですが、事後分布
が入っているので、これが計算できたら苦労しないわけです。最適化計算ができるような戦略を考える必要があり、まず、対数周辺尤度を次のように分解してみます*2。
対数周辺尤度は定数なので、
を最小化するということは、
を最大化するということになります。
ここで、
は次のKLダイバージェンスです。
は素性がわかっているとする関数ですし、
は同時分布なのでどのような関数かわかります*3ので、このKLダイバージェンスなら計算できそうです。
事後分布を近似する関数は、問題によっていくつか考えられるそうです。特に、潜在変数をM個に分割(
)し、それぞれ独立であると考えることが多いと思います*4。これを「平均場近似」と呼ぶそうです。
このように近似をすると、最大化させたいKLダイバージェンスは以下のように変形できます*5。
ということで、潜在変数の部分集合に対する最適関数は以下の通りとなります。
これはj番目の潜在変数の集合の最適解となります。全体を最適化させるには、はじめに初期化を行い、ギブスサンプリング と同様に一つづつM個の関数を更新していきます。
変分推論による近似ベイズ推論の実装
変分推論の適用例として二つの問題を実装してみます。これらは共に解析的に解を導くことができる問題ですが、練習として。
- 1変数ガウス分布のパラメータ推論
- 線形回帰のパラメータ推論
実装例1:1変数ガウス分布のパラメータ推論
モデル
N個のデータが得られており、このデータ
は次のガウス分布
に従うものとします。
ここで、は平均、
は精度(分散の逆数)を示すパラメータの確率変数です。
このようにモデルを設計すると、パラメータの事後分布は次のようになります。
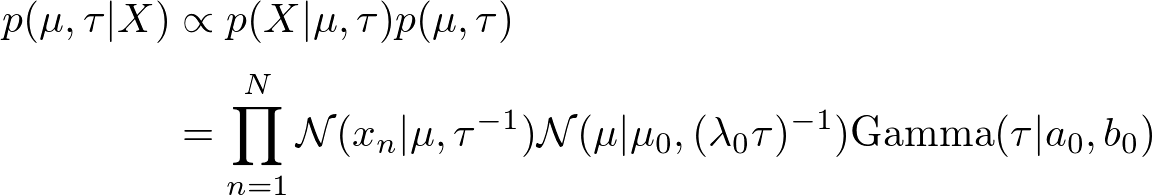
ガウス分布との分布は共役関係にあるので、この事後分布は解析的に導くことができます。ですがここでは練習として、次のように平均と精度を分解(平均場近似)して近似推論してみます。
の最適関数は上述の式に当てはめて、展開して得ます。
平均
に対する最適関数は以下のように展開できます。
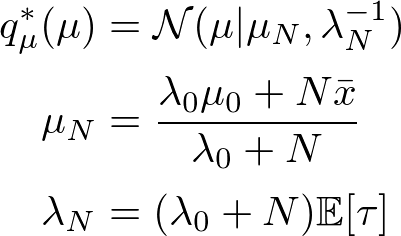
精度に対する最適関数も同様です。

はガウス分布、
はガンマ分布になることがわかりました。
ここで、事前分布のパラメータをとすると
の1次と2次のモーメントは次のようになります。
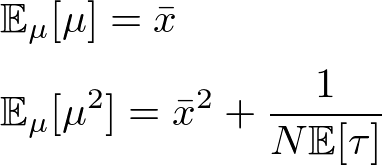
この値を利用してガンマ分布のパラメータを展開すると次の通りとなります。
なお、の期待値は
です。
実装結果
実装コードの全体は実装コード全体にnotebookを貼り付けているので参照してください。
まず、テスト用のデータとして、平均0, 精度0.5のガウス分布から100点のデータをサンプルしました。このデータを利用して推論を行います。
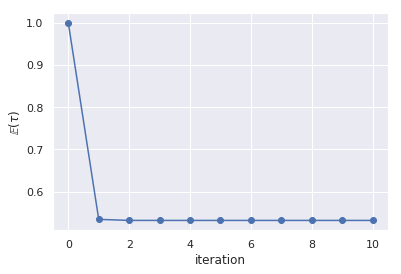
パラメータ推論は、適当に初期値を決めたそれぞれの関数を順々に更新していきます。
def q_mu(X, tau_e): mean_x = X.mean() N = len(X) mu_n = mean_x lambda_n = N * tau_e return mu_n, lambda_n def q_tau(X, tau_e): mean_x = X.mean() mean_x2 = (X**2).mean() N = len(X) a_n = (N + 1) / 2. b_n = (N / 2.) * (mean_x2 - mean_x**2 + (1. / (N*tau_e))) return a_n, b_n tau_e = 1.0 taus = [tau_e] n_iter = 10 for i in tqdm(np.arange(n_iter)): # q(mu) mu_n, lambda_n = q_mu(X, tau_e) # q(tau) a_n, b_n = q_tau(X, tau_e) # E[tau]の更新 tau_e = a_n / b_n taus.append(tau_e)
q_mu(), q_tau()がそれぞれ平均と精度の関数です。先に展開したモデルからtau_e()が更新すべきパラメータです。
の更新系列は、以下のようにすぐにほぼ最適解に収束したようです。
平均と精度の事後分布は以下のように推論できました。
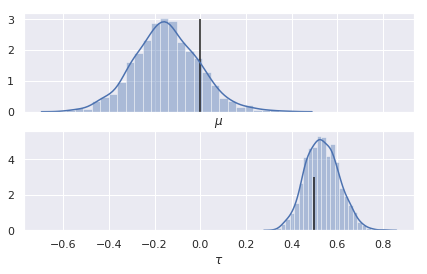
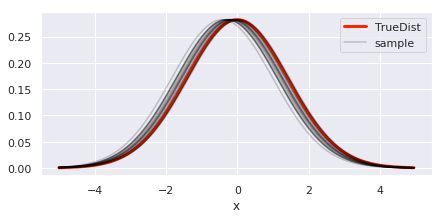
この結果を利用して、事後分布からパラメータをサンプルしてガウス分布を描いてみました。設定値(真の分布)とほとんど同じ分布を推測できていることがわかります。
実装例2:線形回帰のパラメータ推論
前節ではガウス分布のパラメータを推論しました。本節ではもう少しモデルを複雑にして、線形回帰モデルのパラメータ推論を変分推論します*6。
モデル
線形回帰モデルのグラフィカルモデルは以下のものになります。

線形回帰なので、この問題は解析解を得ることができます。また、前回の記事では同じ問題をギブスサンプリング (MCMCアルゴリズムの一つ)で推論しました。よければこちらも参照ください。本記事では解析解の導出は扱わないので。
learning-with-machine.hatenablog.com
まずはモデル(同時分布)を構築します。
今回は、変数Xの1次の線形回帰モデルを扱います*7。
ここで簡単のために、分散は固定のパラメータとします。
重みは未知の確率変数であり、これにも何らかの確率分布を仮定する必要があります。そこで、重み
はガウス分布に従うとし、事前分布として平均0で分散
を与えることにします*8。なお、分散
は固定のパラメータとします。
以上の設定で、データを観測した後での重み
に関する事後分布
を求めることが目的です。
変分近似
変分推論を適用するにあたり、重みをそれぞれ別々に近似していきます。
前章で求めた通り、潜在変数の最適解は以下の通りです。
これに線形回帰のモデルを当てはめると、それぞれの最適解は以下のようになります。
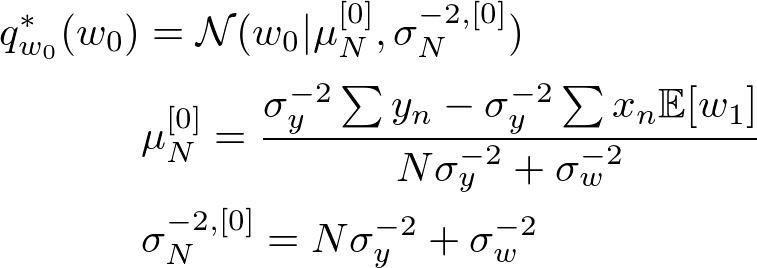
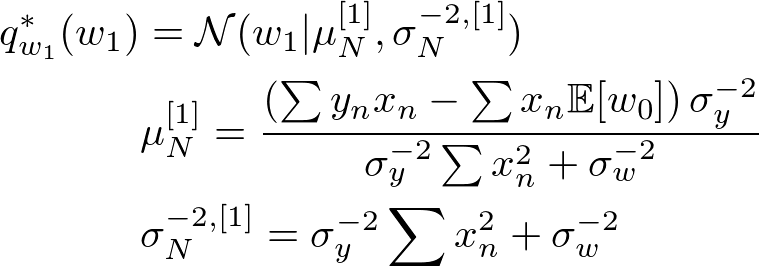
あとはガウス分布のパラメータ推論と同じで、初期値を決めて、それぞれ更新していきます。
実装結果
こちらも実装コードの全体は実装コード全体にnotebookを貼り付けているのでそちらを参照ください。
真の関数としての関数を設定しました。ノイズはガウス分布として、分散
を1.0に設定しました。
この関数から20点のデータをサンプルし、線形回帰のパラメータを推論します。
推論に関するコードは以下の通りです。
def q_w0(X, Y, e_w1, sig2_y, sig2_w): sig2_y_inv = 1.0 / sig2_y sig2_w_inv = 1.0 / sig2_w N = len(X) sig2_n_inv = N*sig2_y_inv + sig2_w_inv sig2_n = 1.0 / sig2_n_inv mu_n = (np.sum(Y) - np.sum(X)*e_w1) * sig2_y_inv * sig2_n return mu_n, sig2_n def q_w1(X, Y, e_w0, sig2_y, sig2_w): sig2_y_inv = 1.0 / sig2_y sig2_w_inv = 1.0 / sig2_w N = len(X) sig2_n_inv = sig2_y_inv * (sample_x**2).sum() + sig2_w_inv sig2_n = 1.0 / sig2_n_inv mu_n = (np.sum(Y * X) - np.sum(X)*e_w0) * sig2_y_inv * sig2_n return mu_n, sig2_n e_w0, e_w1 = 0.0, 0.0 var_w = 0.1 n_iter = 20 mu0s = [e_w0] mu1s = [e_w1] for i in tqdm(np.arange(n_iter)): # q_w0 mu0_n, var0_n = q_w0(sample_x, sample_y, e_w1, var_y, var_w) e_w0 = mu0_n # q_w1 mu1_n, var1_n = q_w1(sample_x, sample_y, e_w0, var_y, var_w) e_w1 = mu1_n mu0s.append(mu0_n) mu1s.append(mu1_n)
それぞれの最適解をq_w0、q_w1という関数で実装しています。初期値を設定してこの二つの関数の推論を繰り返して行くだけです。
今回は式展開を簡単にするために、1次回帰モデルしか扱えないものにしましたが、ギブスサンプリング を実装した記事でやったように基底関数モデルにすることで汎用性が高まります。また、上記のコードでq_w0、q_w1のようにそれぞれ関数を作っているのが冗長ですが、一般解が得られるはずです。
上記のコードを実行した結果、の期待値がどのように収束していったかを確認してみます。
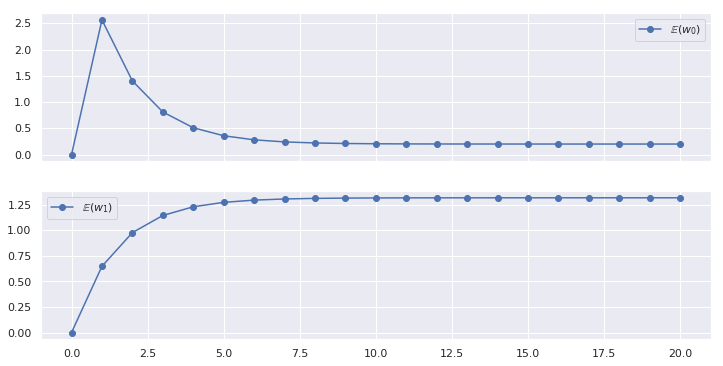
20回の更新の結果得られた事後分布は以下の通りです。
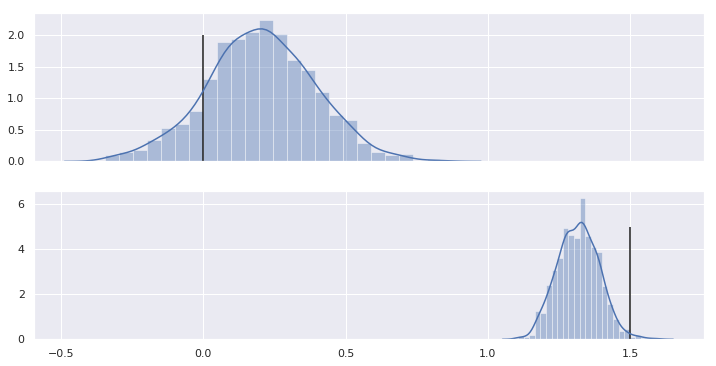
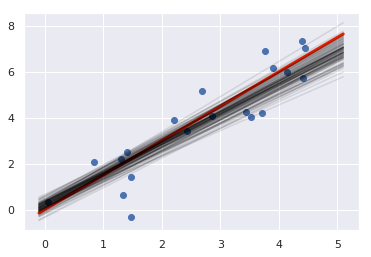
この結果を利用して、事後分布からパラメータをサンプルして推定した関数を描いてみます。設定値と同じような関数を推測できていることがわかります。
実装コード全体
おわりに
ということで、近似ベイズ推論アルゴリズムの一つ、変分推論を実装してみました。
メトロポリス法やギブスサンプリングと比較すると、関数を直接近似するのでサンプルを多量に得るという処理が要らなくなり、高速に推論ができます。
しかし、パラメータの事後分布が既知の関数として展開できない場合にはどのようにするのか、このあたりが私自身がよくわかっていません。引き続き学習を進めていきたいと思います。
何か気づいたことがあれば、ご指摘いただけると助かります。
参考文献
- 作者:須山 敦志
- 発売日: 2019/08/08
- メディア: 単行本

- 作者:C.M. ビショップ
- 発売日: 2012/04/05
- メディア: 単行本(ソフトカバー)
")
- 作者:C.M. ビショップ
- 発売日: 2012/02/29
- メディア: 単行本