【統計検定準一級】統計学実践ワークブックの問題をゆるゆると解く#26
【概要】
【目次】
はじめに
本シリーズでは、いろいろあってリハビリも兼ねて統計学実践ワークブックの問題を解いていきます。 統計検定を受けるかどうかは置いておいて。
今回は11章「正規分布に関する検定」から2問。
なお、問題の全文などは著作権の問題があるかと思って掲載してないです。わかりにくくてすまんですが、自分用なので。
心優しい方、間違いに気付いたら優しく教えてください。
問11.1
問題
2店舗(A, Bとする)を展開するハンバーガーショップがある。ポテトのサイズは120gと仕様が決まっているが、店舗Aはサイズが大きいと噂されている。
無作為に10個抽出して重さを測った結果、平均125g、標準偏差が10.0であった。
以下の設定で仮説検定する。
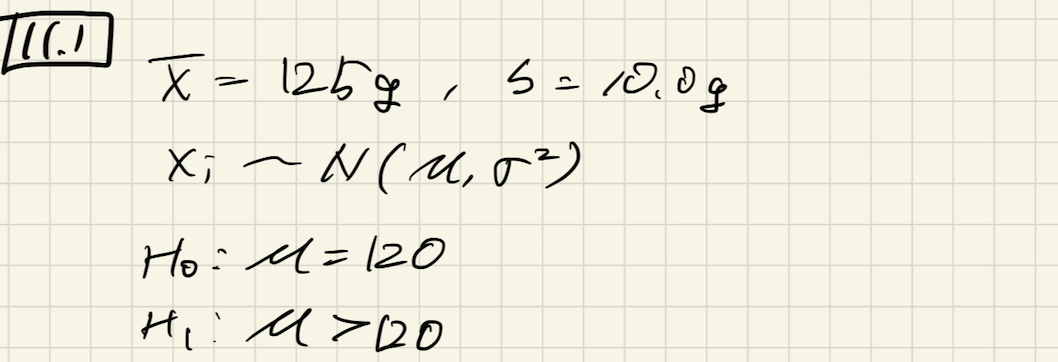
(1) 検定統計量の値は?
補足(1)で書いた検定統計量に当てはめる。

(2) 有意水準を片側2.5%としたときの棄却限界値は?
t分布表から、を読み取れば良い。そのため、2.262となることがわかる。
(3) 帰無仮説は棄却されるか?
(1)で算出したtと(2)で求めたを比較すると、
となるので、
は棄却されない。つまり、店舗Aのポテトのサイズは120gよりも大きいとは言えない。
(4) 有意水準2.5%(片側)で帰無仮説が棄却される最小の標本サイズはいくらか?
統計量をnについて展開すると以下のメモの通りとなります。ただし、は自由度、つまり(n-1)に依存する関数となるので、素直に一つには決まりません。なので、具体的に値を入れて不等式が満たされる最小のnを探します。
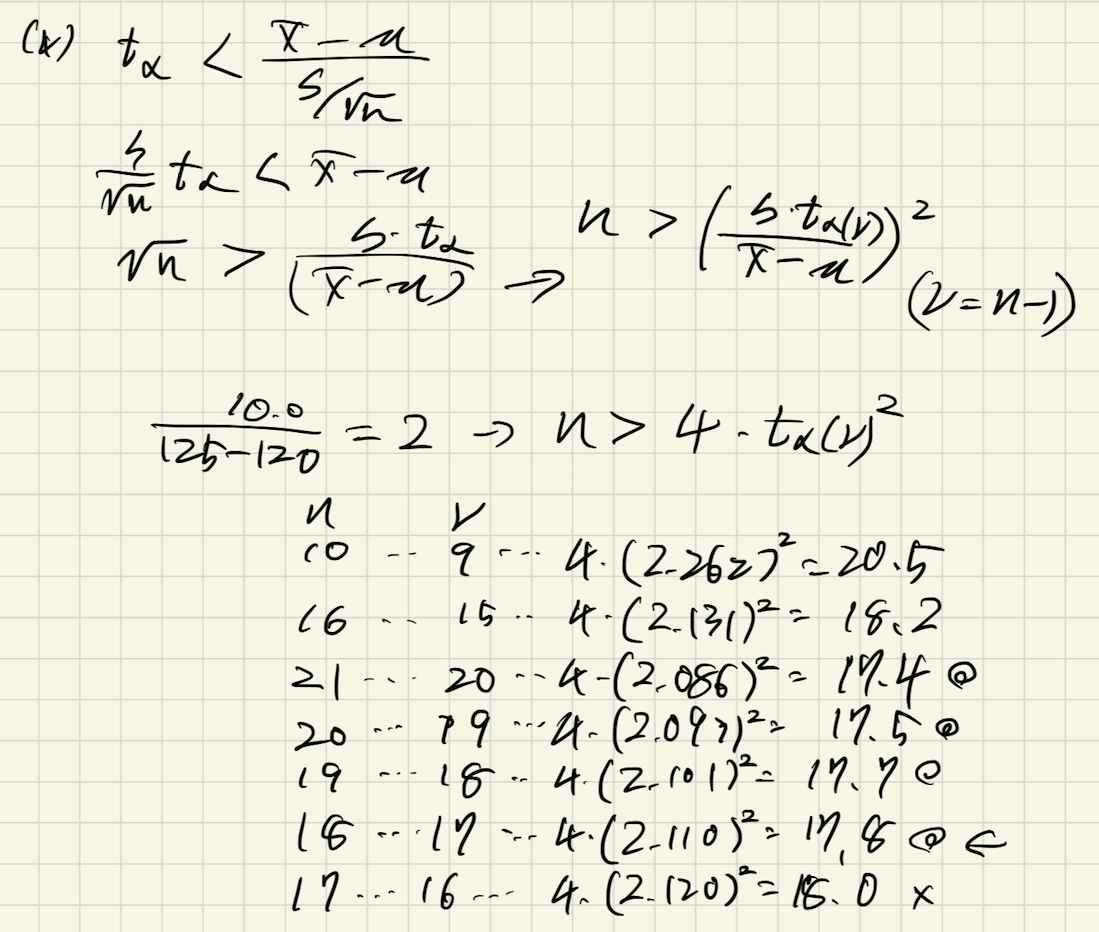
もっと上手い方法ないですかね?
問11.2
問題
問11.1の続きで、店舗Bでも同様に10個のポテトを無作為抽出して重量を計測したところ、平均115g、標準偏差が8.0gだった。
店舗A, Bのポテトはそれぞれと
に従うとする。(分散は共通とする)
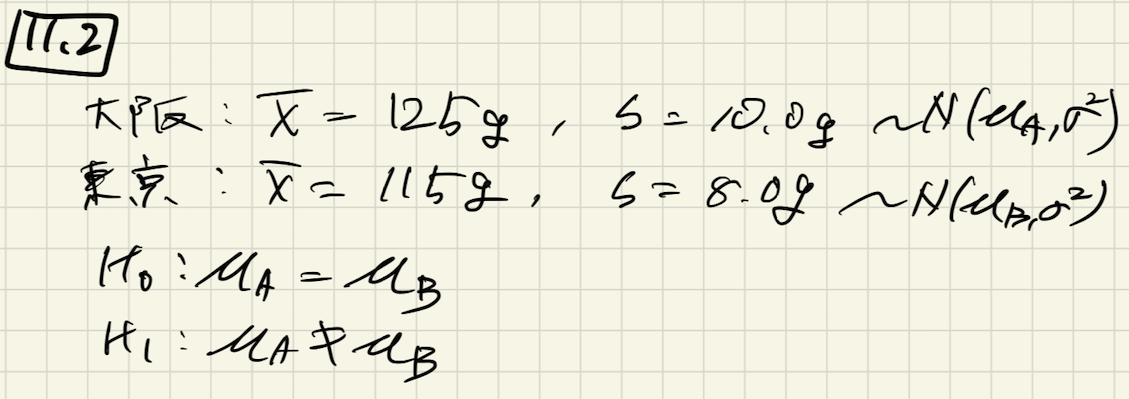
(1) 店舗A, Bのデータを合わせた標本分散を求めよ
2標本の合併分散は、偏差平方和と自由度から以下のメモの通りに定義されます。
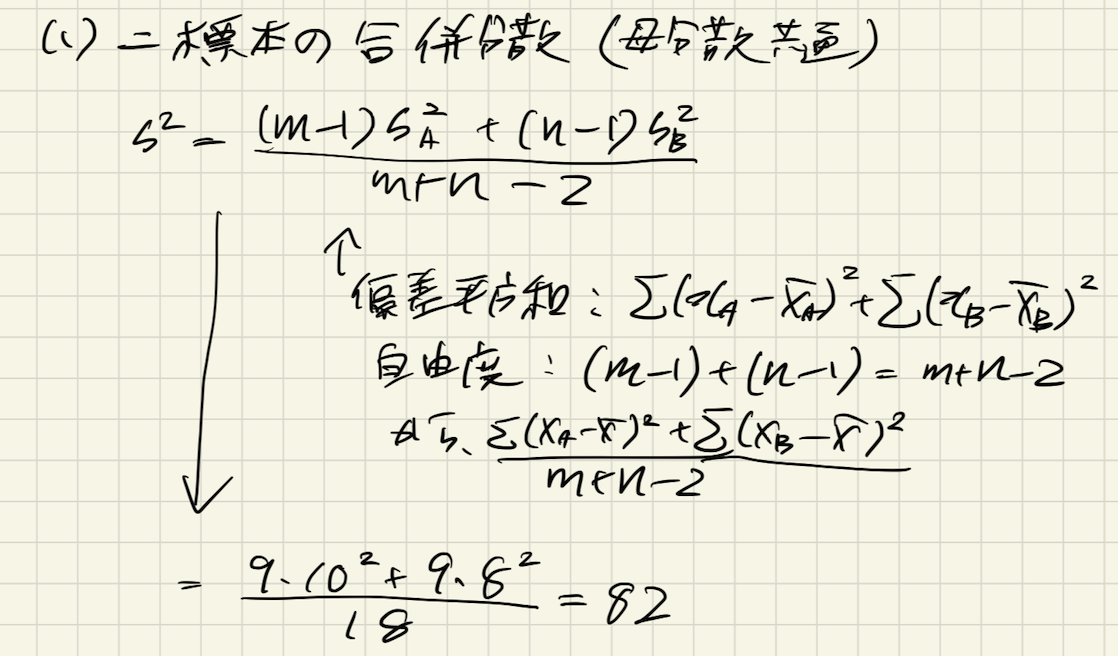
(2) 検定統計量の値を求めよ
補足(2)で求めた式に代入します。
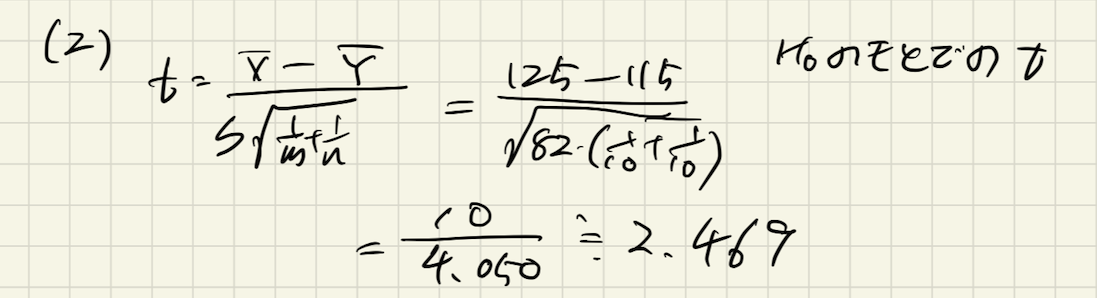
(3) 有意水準5%(両側)としたときの棄却限界値は?
自由度がなので、素直にt分布表から値を探してきます。
(4) 帰無仮説は棄却されるか?
(2)、(3)の結果から、帰無仮説は棄却されることがわかります。
つまり、店舗A, Bのポテトフライの重さは有意水準5%で異なるということが支持されるようです。
補足
(1) t検定統計量
標本平均の分布はに従う。そのため、標準正規分布に変換すると以下のようになる。
分散が未知の場合には、を消去する必要があり、
で割る。
このtは自由度(n-1)のt分布に従う。
(2) 2標本の平均の差が従う分布のt検定統計量
平均の差が従う分布は独立な正規確率変数の和の性質から以下の分布になる。(分散が共通の場合)
補足(1)のt統計量の導出と同様に、分散が未知であるためこれを消去するように加工する。(以下のメモ参照)
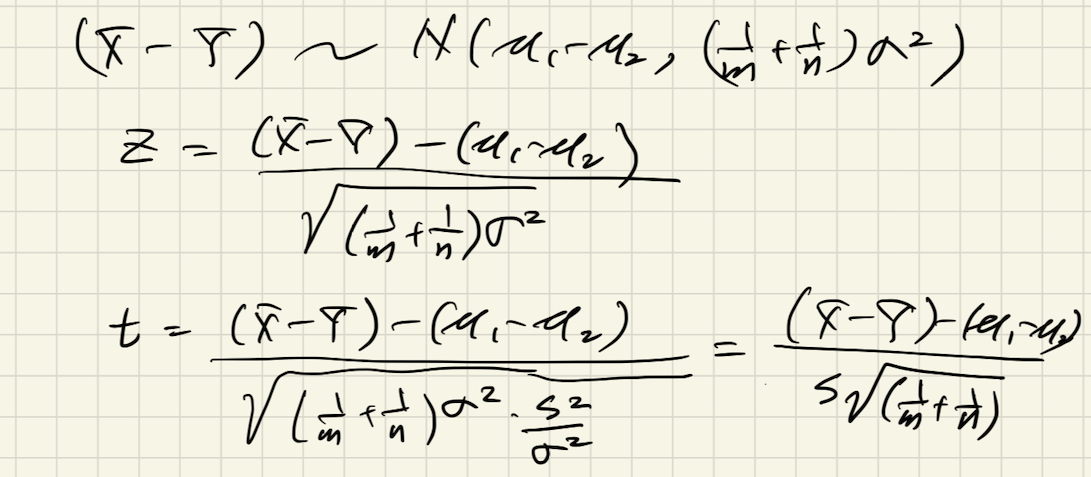
参考資料
【統計検定準一級】統計学実践ワークブックの問題をゆるゆると解く#25
【概要】
- 統計検定準一級対応 統計学実践ワークブックの問題を解いていくシリーズ
- 第24回は10章「検定の基礎」から1問
【目次】
はじめに
本シリーズでは、いろいろあってリハビリも兼ねて統計学実践ワークブックの問題を解いていきます。 統計検定を受けるかどうかは置いておいて。
今回は10章「検定の基礎」から1問。
なお、問題の全文などは著作権の問題があるかと思って掲載してないです。わかりにくくてすまんですが、自分用なので。
心優しい方、間違いに気付いたら優しく教えてください。
問10.3
問題
ある商品の抜き取り検査として、無作為に5個抽出してきて、そのうち2個以上不良品だった場合に、その箱全て不合格とするとの基準を設けたとする。

(1) 不良品率p=0.3の時、不良品が0, 1, 2個出てくる確率
5個の中でr個の不良品が現れる確率ということは、二項分布を考えれば良いです。
二項分布の式に素直に当てはめることで、以下のように算出できます。

(2) p=0.1での生産者危険、p=0.2での消費者危険のそれぞれの確率
市場では、不良率が0.1以下を期待されていると設定されています。
その中で、p=0.1以下でも不合格とされる確率が「生産者危険」です。ここでは、真の不良率p=0.1の時のこの確率を求めよとされていますので、p=0.1の時に、rが2以上になる確率を求めます。なお、テキストには各rでの確率が表になっているので、そのまま足すだけです。

次に、p=0.2以上、つまり、本当は期待以下(不合格品)なのに出荷されてしまう確率が「消費者危険」です。ここでは、真の不良率がp=0.2だった場合のこの確率を求めよとされています。これも上記と同様にp=0.2の時にrが1以上になる確率を求めれば良いです。

参考資料
逆関数法を利用して切断指数分布に従う乱数を取得する
【概要】
- ちょっと切断指数分布に従う乱数が必要になったので、逆関数法を使って乱数を生成する方法をまとめた
【目次】
はじめに
切断指数分布に従う乱数の生成が必要になったのですが、ちょっと調べたところ、切断指数分布に従う乱数を生成するためのAPIはあまり用意されてない?っぽかったです。なので本記事では、逆関数法を使って切断指数分布に従う乱数の生成についてまとめます。
(この記事を書く中でさらに調べたところscipyにtruncexponというAPIが用意されていました。なので、切断指数分布が必要な方はこちらを利用したら良いと思います。。。)
本記事に興味がある方はこちらも参考にしてください。
learning-with-machine.hatenablog.com
切断分布
切断分布とは、値域が切断された確率密度関数です。
正規分布を例にするとこんな感じ。
オレンジ線がの確率密度関数。青線が同じパラメータで-1から1までの領域に限定した切断正規分布。
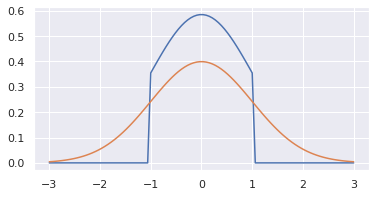
領域が切断されているため、積分して1になるという密度関数の定義を満たすために、値の定義される領域で密度関数の値は切断分布の方が大きくなっています。なので、単純に密度関数を切るだけではないということに注意が必要です。
切断正規分布などは稀に使われているところを見かけます。例えば、事前知識として値の領域が限定されていることがわかっているパラメータの推論をする際の事前分布とか。
逆関数法
逆関数法とは、累積密度関数をの逆関数を利用して、一様分布に従う乱数(一様乱数)から所望の確率密度関数に従う乱数を生成する方法です。

上図を見れば一目瞭然で、乱数を得たい確率密度関数をとして、その累積分布関数
を考えます。
は0から1の範囲の関数なので(確率の定義から)、一様乱数に従うUを
の逆関数
に入力することで、
に従う乱数xに変換することができます。
ということで、逆関数法を利用するには累積分布関数の逆関数を導出する必要がありますが、複雑な関数の場合は解析的に導出することが難しい場合もあります。
この点については、僕が以前書いたブログで、ノンパラメトリックな分布に対して逆関数法を適用してサンプルを取得している例があります。
指数分布と切断指数分布
ここまでで逆関数法がわかったので、指数分布と切断指数分布にそれぞれ従う乱数を取得してみます。
指数分布
指数分布は以下の式で定義されています。
分布関数は、これを積分すればよく、以下の形として知られています。
逆関数は、上記の
をxについて解きます。
これで一様分布に従うUから指数分布に従う乱数を取得できます。
切断指数分布
同様にして切断指数分布を考えます。
切断点をTとして、xが0からTまでの範囲はに比例します。それ以外の領域では0となります。
なので、0からTの範囲で積分して正規化定数を導出します。
累積分布関数は
これでをUとして、xについて解くと
ということで、切断指数分布に従う乱数を得るための変換式を導出できました。
試してみる
詳細は以下のnotebookを参照してください。

こんな感じで、それぞれの分布に従う乱数を生成できました。
「はじめに」でも書きましたが、scipyにはtrancexponという関数が用意されているみたいです。ということで、scipy使えば逆関数法による導出は要らなかった。。。
【統計検定準一級】統計学実践ワークブックの問題をゆるゆると解く#24
【概要】
- 統計検定準一級対応 統計学実践ワークブックの問題を解いていくシリーズ
- 第24回は10章「検定の基礎」から1問
【目次】
はじめに
本シリーズでは、いろいろあってリハビリも兼ねて統計学実践ワークブックの問題を解いていきます。 統計検定を受けるかどうかは置いておいて。
今回は10章「検定の基礎」から1問。
なお、問題の全文などは著作権の問題があるかと思って掲載してないです。わかりにくくてすまんですが、自分用なので。
心優しい方、間違いに気付いたら優しく教えてください。
問10.2
問題
あるメーカの既製品Aと新製品Bの重さXは独立に正規分布に従っているとする。それぞれ16個をランダムに抽出して偏差平方和[tex:T2]を算出した。
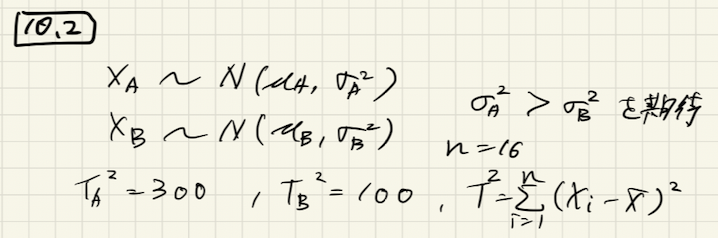
(1) 新製品Bの分散の95%信頼区間を求めよ
偏差平方和を分散で割った値は自由度(n-1)のカイ二乗分布に従います(以下のメモ参照)。

ということで、カイ二乗分布表を使って、95%区間を求めると以下のメモの通りとなります。

(2) 新製品の方が分散が小さいという主張を検定せよ
実際のテキストの問題では穴埋めの問題になっていますが、分散の比について検定してみます。
新製品の方が分散が小さいという主張なので、帰無仮説、対立仮説
は以下の通りとなります。

(1)で扱ったように、偏差二乗和[tex:T2]は自由度(n-1)のカイ二乗分布に従います。
なので、フィッシャーの分散比をH0について求めると、検定統計量はF分布(
)に従うことがわかります。
ということで、検定統計量とF分布表から、帰無仮説は棄却できることがわかります。つまり、新製品の方が分散が小さいという主張が正しそうだと支持されます。

参考資料
【統計検定準一級】統計学実践ワークブックの問題をゆるゆると解く#23
【概要】
- 統計検定準一級対応 統計学実践ワークブックの問題を解いていくシリーズ
- 第23回は10章「検定の基礎」から1問
- この章も長くなりそう。。。
【目次】
はじめに
本シリーズでは、いろいろあってリハビリも兼ねて統計学実践ワークブックの問題を解いていきます。 統計検定を受けるかどうかは置いておいて。
今回は10章「検定の基礎」から1問。
なお、問題の全文などは著作権の問題があるかと思って掲載してないです。わかりにくくてすまんですが、自分用なので。
心優しい方、間違いに気付いたら優しく教えてください。
検出力
今回の問題では、検出力を導出せよとされています。そこでまず先に、検出力についてまとめていきます。
検出力についてはここまで参考にしていたテキストでどうしても理解ができず、参考文献2をあたりました。検定周りがどうにも理解ができていなかったのですが、この書籍はだいぶわかりやすかったので超絶おすすめです。
検定における2種類の誤り
統計的仮設検定では、限定的な形で帰無仮説H0を設定し、H0が棄却(H0は成り立たないと判断)できた場合に、対立仮設H1が支持できるだろうと考えます。(詳しくは何らかのテキストを見て)
この時、H0, H1が本当に成り立っているか、検定結果として棄却できるか否かの組み合わせで次の四通りあります。
- 本当はH0が成り立っているときに、検定結果としてH0が棄却できなかった(望んだ結果)
- 本当はH0が成り立っているときに、検定結果としてH0を棄却してしまった(間違い、この確率をαとする)
- 本当はH1が成り立っているときに、検定結果としてH0が棄却できなかった(間違い、この確率をβとする)
- 本当はH1が成り立っているときに、検定結果としてH0を棄却した(望んだ結果)
検定結果の誤りは上記2,3です。2は「第1種の過誤」、3は「第2種の過誤」と呼ばれています。この概念が重要です。
第1種の過誤はわかりやすくて、帰無仮説H0を設定した元で、手元にあるデータがH0を前提とした際に非常に小さい確率でしか発生しない(これを有意水準と呼び、だいたい5%とかにすると思います)となれば、H0が棄却されます。5%が「小さい確率」かどうかは分野によって違うと思いますが、5%の確率で誤判断してしまう可能性があるということになります。これが第1種の過誤です。
H0の元で確率α(有意水準)以下の確率か否かを判断するわけですが、H0とH1が共に近い仮説なら、本当はH1が成り立っているのにH0でも十分に起こり得るデータであり、H0を棄却できない状態というのはありえます。(なので、H0が棄却できないからといってH0が支持されているとは限らないということ)

「検出力」というのは、第2種の過誤を起こす確率βがどれだけ小さいかを示し、「第2種の過誤が発生しない確率()」として定義されています。
検出力の導出
仮説として、以下のH0, H1を考えます。
- 帰無仮説
- 対立仮説
手元に標本サイズNの標本があるとします。この標本の平均を標準化したものをとして、帰無仮説[tec:H_0]の下での
を
とします。

仮説検定では、このが有意水準
以下の確率で生じるのかを算出します。

検出力は、
の下で、
を棄却する確率となります。

検出力の導出結果をさらに変形させていくと、サンプルサイズ、エフェクトサイズ(上記メモの
)、標準正規分布における棄却点
で構成される式が導出できます。

ということで、この式を利用して、サンプルサイズの設計や検出力の導出を行います。
問10.1
問題
ある政党支持率の調査の結果、先月の支持率は0.45だった。
今月の支持率は0.5になってるんじゃないかという主張がされている。
(1) 帰無仮説として 、対立仮説として
、対立仮説として としたときの検出力はいくらか?
としたときの検出力はいくらか?
今回の問題では、検定の仕様として次の設定がされています。
- 検定の種類: 両側検定(対立仮設の種類としてp≠p0が設定されているとみられる)
- 有意水準: 5%
- サンプルサイズ: 600
データは、政党を支持するかしないかということで、ベルヌーイ分布となります。この平均が支持率となるわけなので、中心極限定理から検定統計量zは以下のメモの通り標準正規分布に従うことがわかります。

検出力は上記で導出したとおり当てはめていきます。

(2) 検出力を80%以上にするために必要なサンプルサイズを求めよ
検出力を設定したうえでのサンプルサイズについては、上記の式をサンプルサイズnについて展開することで導出できます。

参考資料
")
【統計検定準一級】統計学実践ワークブックの問題をゆるゆると解く#22
【概要】
【目次】
はじめに
本シリーズでは、いろいろあってリハビリも兼ねて統計学実践ワークブックの問題を解いていきます。 統計検定を受けるかどうかは置いておいて。
今回は9章「区間推定」から1問。
なお、問題の全文などは著作権の問題があるかと思って掲載してないです。わかりにくくてすまんですが、自分用なので。
心優しい方、間違いに気付いたら優しく教えてください。
問9.2
問題
(本当の調査結果は知らないですが)「最も好きなスポーツ選手」の調査結果に基づいて、区間推定をします。
調査の回答者は1,227人で、そのうち有効回答数は917人ということです。
(テキストに記載されている調査結果はここでは掲載しません)
(1) イチロー選手が最も好きな人の割合の95%信頼区間を求めよ
調査結果として、最も好きな選手の1位はイチロー選手ということでした。
| 選手名 | 得票数 | 割合 |
|---|---|---|
| イチロー | 240 | 0.262 |
前回行ったのと同様に、95%信頼区間を計算します。z-scoreの導出が気になる方は前回を参照してください。

(2) 1位のイチロー選手と2位の羽生結弦選手の割合の差の95%信頼区間を求めよ
2位までの調査結果は以下の通りということです。
| 選手名 | 得票数 | 割合 |
|---|---|---|
| イチロー | 240 | 0.262 |
| 羽生結弦 | 73 | 0.08 |
信頼区間を求めるためには、知りたい確率変数を標準正規分布に押し込めるように考えます。ここで知りたい確率変数は、なので、この確率変数の期待値と分散を導出します。
期待値は容易に導出できます。ベルヌーイ分布に従う確率変数の標本平均(最尤推定量)は一致推定量となることを利用しました。

分散は、が独立ではないため、共分散
成分を考慮する必要があります。共分散は以下のメモのように分解されます。

ここで、N1, N2の期待値は明らかですが、は自明ではありません(テキストではここが書かれてない!)。なので、導出してみます。
期待値なので、確率分布を考える必要があります。これは、多項分布において
となる確率なので、以下のメモ(上部)のように変形できます。
次に総和の中身は、総和に関係しない成分を取り出すと、多項定理を利用して単純な形に変形することができます。するとこの部分は1になるということがわかりました。

ということで、共分散成分がわかったので、分散を導出することができました。

期待値と分散が求まったので、標準正規分布を考えると以下のメモのように95%信頼区間を導出することができました。

参考資料
【統計検定準一級】統計学実践ワークブックの問題をゆるゆると解く#21
【概要】
【目次】
はじめに
本シリーズでは、いろいろあってリハビリも兼ねて統計学実践ワークブックの問題を解いていきます。 統計検定を受けるかどうかは置いておいて。
今回は9章「区間推定」から1問。
なお、問題の全文などは著作権の問題があるかと思って掲載してないです。わかりにくくてすまんですが、自分用なので。
心優しい方、間違いに気付いたら優しく教えてください。
問9.1
問題
内閣支持率の世論調査を実施し、1,240人から回答があった。この回答を集計すると支持率は43%であった。(本当の調査かは知らないです)

(1) 回答者が母集団からの無作為抽出であると仮定したとき、95%信頼区間を求めよ
確率pで支持、(1-p)で不支持とすると、43%という集計結果は二項分布に従うことになります。
二項分布はベルヌーイ分布に従う確率変数の和となるので、中心極限定理からこれは正規分布で近似できることがわかります。
すると、二項分布の期待値と分散から、標準正規分布に従うz-scoreを導出できます。

このz-scoreが95%信頼区間の標準正規分布での下限と上限にかかる値を求めることで、信頼区間がもとまります。

この辺りの証明は、参考文献2を参考にしました。
(2) 支持率が40%前後と仮定したとき、95%信頼区間が2%となるために必要なサンプルサイズを求めよ
信頼区間の範囲から、幅は以下の式の通りとなります。
ここで、1.96は95%信頼区間なので1.96です。標準正規分布での2.5%, 97.5%の位置ですね。

参考資料
[1] 日本統計学会, 統計学実践ワークブック, 2020, 学術図書出版社

日本統計学会公式認定 統計検定準1級対応 統計学実践ワークブック
- 発売日: 2020/05/29
- メディア: 単行本
")
- 発売日: 1991/07/09
- メディア: 単行本