系列データの統計モデリング 〜カルマンフィルタとパーティクルフィルタの比較〜
【概要】
- 系列データのモデリングと状態推定のシリーズ5回目
- 今回は、カルマンフィルタとパーティクルフィルタの比較をやってみます
【目次】
はじめに
統計モデリングを行うにあたって、独立同分布(i.i.d; independent and identically distributed)を仮定することが多いと思います。
しかし、i.i.dを仮定できないケースはよくあります。時系列などの系列データが代表的です。また、i.i.dを仮定することが多い対象でも、計測対象や計測装置の経時的な変化(劣化)など本来的には系列を考慮しないといけない場面はあると思います。
系列データの解析について、主に「予測にいかす統計モデリングの基本」を参考に確認しましたので、数回に分けてまとめていこうと思います。なお、状態空間モデル(State Space Model)を使ったモデリングが対象です。
前回はカルマンフィルタの導出と実装を行い、簡単な状態空間モデルの推論を試行してみました。今回は、パーティクルフィルタとカルマンフィルタを比較してみようと思います。今回扱うトイデータは、線形ガウス状態空間モデルに従うため、推論結果はどちらもだいたい同じになります。計算速度やパーティクルフィルタの近似精度などをみてみます。
間違いや勘違いなど、なにかありましたら指摘いただけるとすごく助かります。
問題設定
今回はカルマンフィルタとパーティクルフィルタの推定結果を比較してみます。扱うトイデータはこれまでのシリーズで扱ってきたものと同じデータです。

こちらのデータは、以下の1次元の線形ガウス状態空間モデルからサンプルしたものです。なので、カルマンフィルタを使うことで完全に推定ができるはずです。
状態推定
状態推定についての詳細は、以下の記事を参照ください。
系列データの統計モデリング 〜カルマンフィルタ の導出と実装〜 - 機械と学習する
系列データの統計モデリング 〜パーティクルフィルタによる状態推定〜 - 機械と学習する
実験に使ったjupyter notebookを巻末に添付しています。よければそちらもご覧いただけたらと思います。
比較
前章で推論した結果を比較してみます。先に書いた通り、今回のトイデータはカルマンフィルタを使うことで推論できることはわかっています。なので、パーティクルフィルタのパラメータ毎の計算時間と推定精度の差に注目してみます。
実験環境
- MacBook Pro
- Docker Desktop 2.4.0.0
- Python 3.8
計算時間
計測は簡単にtqdmを使ってプログレスバーの表示から読み取ります。
| type | iteration | 計算時間(sec) |
|---|---|---|
| KarmanFilter | 200 | 0.02 |
| ParticleFilter(1,000) | 200 | 178.57 |
| ParticleFilter(50) | 200 | 9.51 |
ParticleFilterの括弧の中はパーティクル数を表します。iterationが200なのは、データ数が200点だからです。
ということで、カルマンフィルタは平均と分散を算出するだけなので高速です(あたりまえ)。 パーティクルフィルタはパーティクル数分の繰り返し計算が入るので、その分時間がかかりますね。仕組みから明らかに、パーティクル数に対して線形に計算量が増えます。 ただ、これは実装の問題で、今回の実装は工夫はあまりなくて愚直に計算しています(第1回を参照ください)。パーティクル毎に直列に計算しているのですが、ここは並列ができると思います。
平均と標準偏差の比較
次に、推定した平均と標準偏差を比較してみます。 問題設定からこのデータはガウス状態空間モデルになるので、平均と分散を出すことができます。
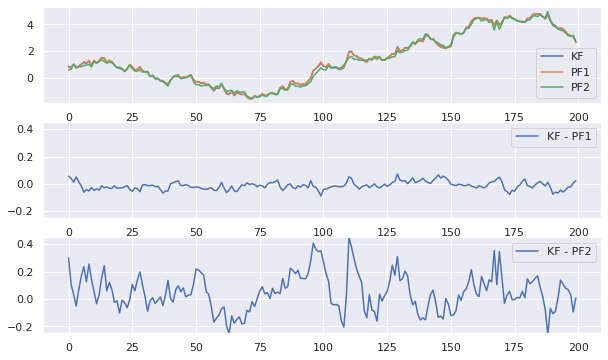
上の推定結果をみると、ちょっとわかりにくいですが、カルマンフィルタとパーティクル数1,000のパーティクルフィルタはほぼ推定結果が重なっています。パーティクル数を50にするとちょっと近似精度の低さが見える箇所がありますね。これを表現したのがその下の二つの図です。
次に標準偏差をみてみましょう。
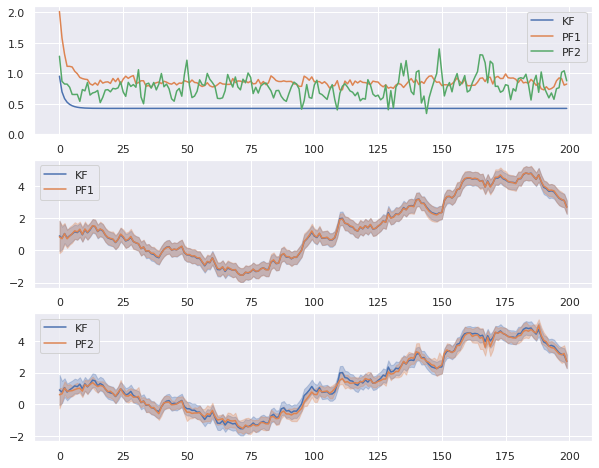
上図の下二つのプロットがわかりやすいかと思います。
標準偏差の範囲なので、パーティクルフィルタの場合はパーティクル集合の15.85%点と84.15%点を予測幅としてプロットしています。この図から、パーティクル数を1,000までにするとカルマンフィルタとほぼ一致するということがわかります。
比較のまとめ
カルマンフィルタとパーティクル数の異なる二つのパーティクルフィルタの推論結果を比較してみました。パーティクル数が増えれば近似精度が向上するということがよくわかりましたが、その分計算時間が問題となります。 これはパーティクルフィルタを扱う上では頻繁に問題になるトレードオフなので、実験的にちょうど良いバランスを見つけるのが必要ですね。
あと、ガウス状態空間モデルとして表現できそうなら、カルマンフィルタ使えば良いということですね。
推論と比較のnotebook
標準偏差の実数がカルマンフィルタとパーティクルフィルタで誤差が大きいので、ここ何か勘違いしている可能性が高いので注意してください。
おわりに
ということで、線形ガウス状態空間モデルの推論について、カルマンフィルタとパーティクルフィルタの比較をやってみました。
結論だけみると、推論結果はだいたい一緒でしたが、カルマンフィルタの計算時間が圧倒的でした。しかし、これは単純な線形ガウス状態空間モデルを扱ったからです。一般の状態空間モデルに応用しようとすると、ガウス状態空間モデルで十分モデル化できるのかは議論が必要なところであり、そういう場面ではパーティクルフィルタが効果を発揮するはずです。
参考資料
[1] 樋口(著), 予測にいかす統計モデリングの基本―ベイズ統計入門から応用まで, 講談社, 2011
")
予測にいかす統計モデリングの基本―ベイズ統計入門から応用まで (KS理工学専門書)
- 作者:樋口 知之
- 発売日: 2011/04/07
- メディア: 単行本
[2] Sebastian Thrun(著), Probabilistic Robotics, MIT Press, 2005
")
Probabilistic Robotics (Intelligent Robotics and Autonomous Agents series)
- 作者:Thrun, Sebastian,Burgard, Wolfram,Fox, Dieter
- 発売日: 2005/08/19
- メディア: ハードカバー