【統計検定準一級】第8章 統計的推定の基礎 #2【番外編】
【概要】
- 統計検定準一級対応 統計学実践ワークブックの問題を解いていくシリーズの番外編
- 8章「統計的推定の基礎」の内容をまとめます
- 今回は推定法として「最尤法」と「モーメント法」について
【目次】
はじめに
「統計学実践ワークブック(参考資料1)」の問題を解いていくシリーズをやっていく中で、8章「統計的推定の基礎」の内容をさっぱり理解していないことがわかったので、改めて整理しています。
参考にした資料は参考文献に列挙しています。中でも主に文献4を参考にしています。
心優しい方、間違いに気付いたら優しく教えてください。
8章の流れ
統計の目的の一つとして、「未知パラメータの推定」という問題があり、この章ではその中でも「点推定」について扱っています*1。「区間推定」については9章で扱われています。
- 情報の集約
- 推論を行うにあたって、生データを全て保存するのではなく、情報を集約できればうれしい(メモリ的に)
- → 「十分統計量」
- 推定法
- パラメータの点推定を行うためにはいくつか方法がある
- → モーメント法
- → 最尤推定
- 推定量の評価、推定量の性質
この流れに沿って、確認内容をまとめていこうと思います。
今回は、実際に未知パラメータの推定法として「モーメント法」と「最尤法」について。
パラメータ推定
前提として、データがなんらかのパラメータで規定された確率モデルから生成されているとします。このようなモデルは「パラメトリックなモデル」と呼ばれています。
モデルとして正規分布を設定すれば、パラメータはμとσの二つです。統計的推定では、確率モデルのパラメータ
をデータから推定する問題を扱います*3。
推定法: モーメント法
r次のモーメントとは、確率変数のr乗の期待値です。
r次のモーメントをパラメータの関数
として表現します。なお、
です。
ここで、r次のモーメントを以下のように近似します。
これらを合わせるとk個の方程式ができるので、その連立方程式を解くことでパラメータの推定値を得るというのがモーメント法ということです。
ベルヌーイ分布のパラメータ推定の例
ベルヌーイ分布は、パラメータがイベント発生確率
ひとつだけの確率分布です。ベルヌーイ分布に従う確率変数Xの期待値は
なので、結局以下の通りとなります。

正規分布のパラメータ推定の例
正規分布はパラメータが平均と分散[tex:\sigma2]の2つです。
Xの期待値はμですが、]は分散
]から
となります。
ということで、以下のメモのように分散が標本分散として推定できることがわかりました。
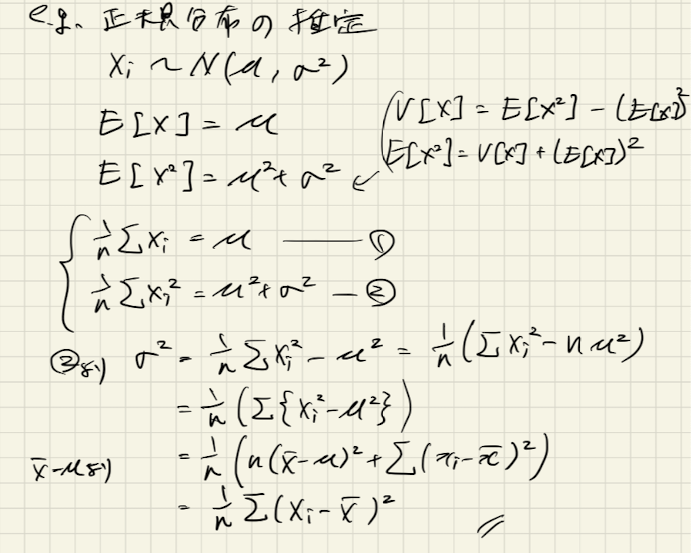
推定法: 最尤法
サンプルの同時確率を尤度(likelihood)
と呼び、尤度が最大になるパラメータθを推定値とするのが最尤法です。
尤度を最大化する意味としては、手元にあるデータが得られる確率が高いパラメータを持ったモデルを選択するのが合理的でしょうという考えに基づいています。このような考えを「最尤原理」と呼ぶと理解しています。
尤度関数を最大化するパラメータを求めるということで、以下のメモのように、パラメータで偏微分して0とした連立方程式を解きます。このとき、尤度関数は総積で表現されるため計算がややこしくなるので、対数をとった対数尤度を使うことが多いです。

ベルヌーイ分布のパラメータ推定の例
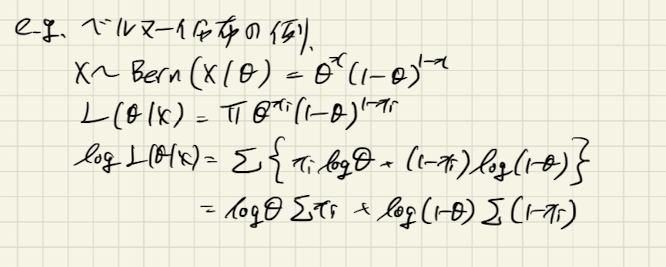
正規分布のパラメータ推定の例
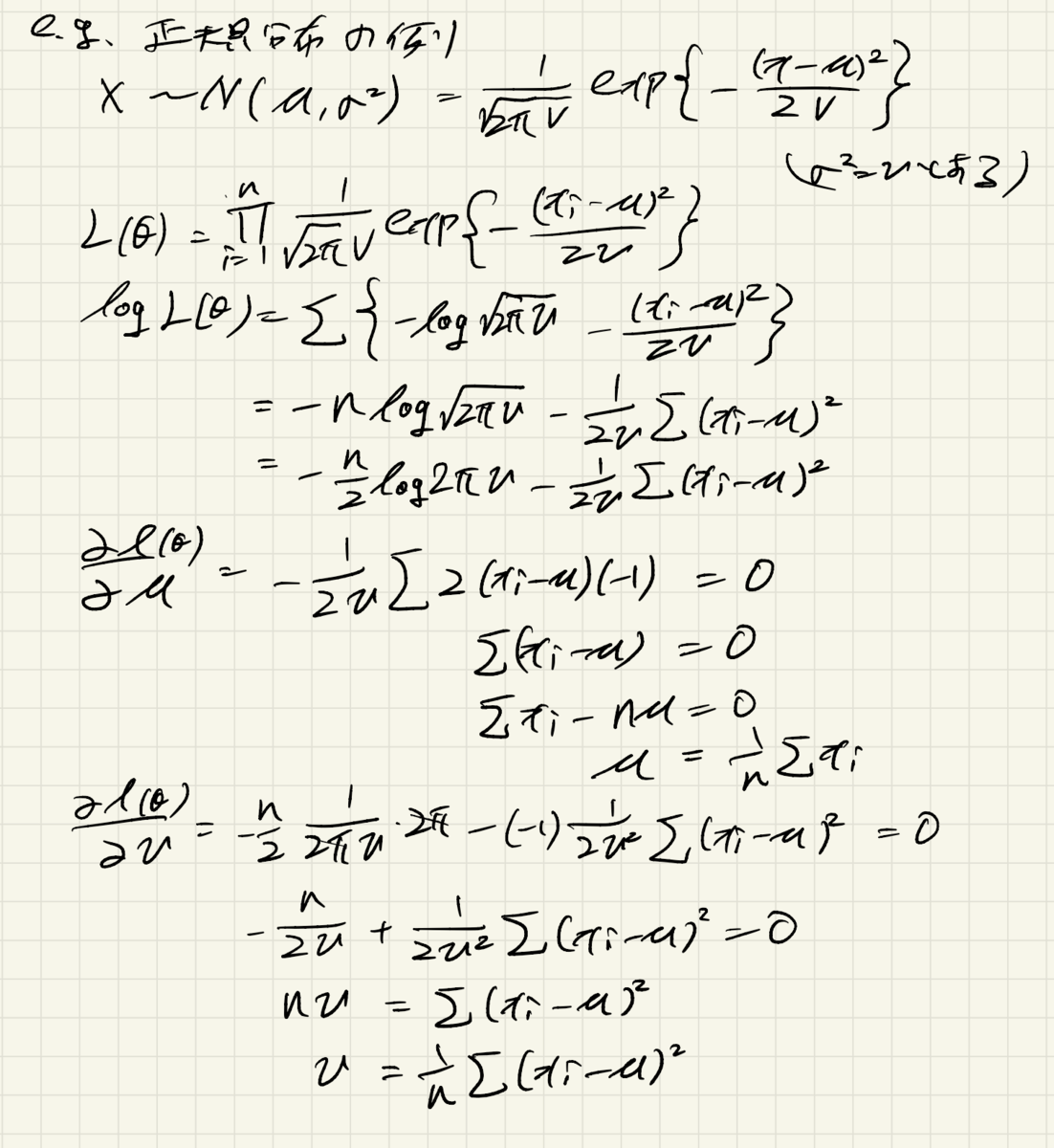
参考資料
[1] 日本統計学会, 統計学実践ワークブック, 2020, 学術図書出版社

日本統計学会公式認定 統計検定準1級対応 統計学実践ワークブック
- 発売日: 2020/05/29
- メディア: 単行本
")
- 発売日: 1991/07/09
- メディア: 単行本
[3] 矢島ら, 自然科学の統計学, 1992, 東京大学出版会
")
- 発売日: 1992/08/01
- メディア: 単行本
[4] 久保川, 現代数理統計学の基礎, 2017, 共立出版
")
- 作者:達也, 久保川
- 発売日: 2017/04/07
- メディア: 単行本
[5] 竹村, 現代数理統計学, 2021, 学術図書出版社

- 作者:彰通, 竹村
- 発売日: 2020/11/10
- メディア: 単行本